


Most organizations store and maintain internal data from applications, operational systems, and CRM platforms, using traditional OLTP(Online Transactional Processing) databases to support transactional processing and day-to-day business operations. However, as businesses expand, the volume of generated data grows exponentially, leading to the need to handle Big Data, characterized by Volume, Velocity, Variety, and Veracity. In this blog, we explore the differences, benefits, and use cases when comparing Data Lake vs Data Lakehouse vs Data Warehouse. Further, we look into providing insights on which architecture would best suit the different use cases.
Unlock AI-driven insights with scalable and cost-effective solutions
Traditional Databases such as MySQL, SQL Server, and PostgreSQL are designed for transactional processing systems and struggle with large-scale analytical queries. To address this, organizations need analytical databases or a Data Warehouse that can consolidate data from multiple sources. These systems can also efficiently handle large query loads and provide meaningful insights. Alternatively, Data Lakes were introduced to provide optimal, cost-effective storage solutions, ideal for machine learning, and big data use cases. Then entered Data Lakehouses, bringing the best of both worlds. Let’s take a look at each of these transformative data solutions for enterprises.
Data Warehouse
Data Warehouse (OLAP – Online Analytical Processing) provides a platform with faster access to data through SQL-compatible queries. Business users, internal stakeholders, and data scientists predominantly use it for accurate reporting insights, AI/ML model development, different data-specific use cases, and data products. Before users can consume the data from their end product, such as reports, ML models, etc., it will go through a few steps to restrict it to a specific format, schema, and best practices, avoiding any unnecessary cost increases due to storage and query.
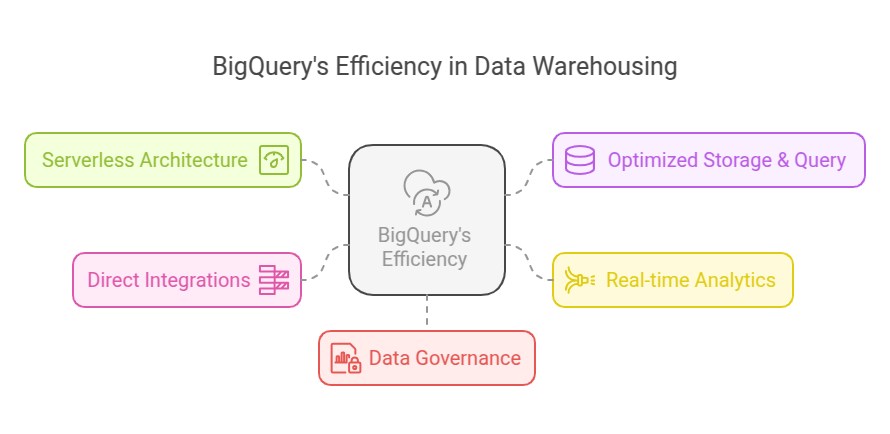
Image 1: Why BigQuery is Efficient for Data Warehousing
BigQuery – The Data Warehouse for Enterprises
There are many features that make BigQUery uniquely positioned for enterprise data. These include –
- Serverless architecture: BigQuery’s Serverless architecture enables independent scaling of storage (Colossus) and compute (Dremel) clusters, ensuring flexibility and cost control. This provides both flexibility to scale the clusters on demand and cost controls. BigQuery stores the data in the columnar format (capacitor) which makes it efficient to store queries in large volumes of data, unlike traditional storage which stores the data in a row-by-row structure.
- Optimized Storage & Query: As part of the best practices, to optimize the query performances and reduce costs, BigQuery optimizes the underlying tables by partitioning (dividing larger tables into smaller chunks, based on the specific field value, which can be identified by the column that gets grouped more) and clustering (often helps with faster querying and reduce the amount of data scanned by organizing the values based on the partitions).
- Real-time analytics: BigQuery is compatible with streaming inserts with built-in support for APIs and pipelines, so the end users need not wait for the batch processing to get real-time analytics. Materialized views can be created as pre-computed views that will be auto-reflected based on the event-driven updates, enabling a real-time dashboard by focusing on the delta updates instead of full data scans.
- Direct Integrations: Built-in connector supports downstream business intelligence tools such as Google’s Looker Studio, Tableau, and many more. Native connectors are supported to export the data to third-party services such as Google Sheets, and local files. BigQuery also seamlessly integrates with Vertex AI to perform ML use cases. BigQuery’s Machine Learning capabilities provide a way for the users to create, train, and deploy the ML models using SQL without exporting data to external platforms. BigQuery client SDK enables users to directly integrate with the existing application and query from the same.
- Data Governance: BQ natively supports strong data governance features to ensure enforcement of security, compliance, access management, and maintaining data integrity. Its integration with Dataplex offers many more features from governance aspects like data cataloguing, data lineage, data quality, and observability.
Limitations of Traditional SQL Databases for Data Warehousing
Traditional SQL Databases can also be made to act as a warehouse but are not recommended due to their:
- Performance limitations: OLTP optimized for day-to-day transactions cannot handle large-scale analytical queries efficiently.
- Historical Analysis: It only stores current operational and transactional data, making it difficult to track trends over time.
- Integrations: Business organizations collect data from multiple systems as a source, but using the OLTP may lead to data silos.
- Data Consistency: Raw data from multiple sources need to be cleaned, cleansed, and processed with the ETL pipeline to maintain consistency in data, which can be challenging to implement in the transactional system.
Emergence of Data Lakes
A Data Lake provides more flexibility and scalability in terms of storage solutions that can hold any kind of unstructured and semi-structured data, processing the data in bulk to consume for various purposes. This is ideal for big data processing, machine learning use cases, and value-added predictive analytics, making it foundational for AI-driven architectures.
A Data Lake efficiently stores the data from third-party services like IoT devices, logs data, social media data, videos, etc. It provides cost-effective storage and a unified solution to that combines the above sources after being processed in bulk. This method preserves both unstructured, raw, and semistructured data, without transforming it for enhanced future data processing functions. The efficient handling of large datasets through batch processing enables organizations to execute data cleaning and analysis steps for AI, machine learning as well as business intelligence applications.
As organizations generate massive data over time, managing their exponential growth will be crucial. Data Warehouses can struggle with scale, whereas Data Lakes are designed to overcome these limitations.
- Storage cost: With the exponential rise of data from different data producers, storing in Data Warehouses can be expensive compared to Data Lakes, as it offers scalable, low-cost storage for diverse data types.
- Rigid due to wide schema: Data storage management in the Data Warehouse is rigid due to its schema-on-write restrictions, whereas Data Lake offers schema-on-read where raw data can be stored as-is and structured later.
- BigData processing: While a Data Warehouse is ideal for analytical use cases, a Data Lake supports bulk data processing in batch at lower cost, which is efficient for Machine Learning use cases.
Data Lakehouses
Data lakes and data warehouses cannot be leveraged together as it may cause data silos. For example; storing clickstream events in the object storage, and querying the same, further ingesting them to a Data Warehouse for querying, leads to data duplication and higher storage costs. This is where data lakehouses come in.
The Data Lakehouse concept combines the above two approaches of Data Warehouse and Data Lake to provide a single solution to capture all types of data (structured, unstructured, and semi-structured) enabling a unified data platform.
Data Lake vs Data Lakehouse vs Data Warehouse: Key Differences & Use Cases
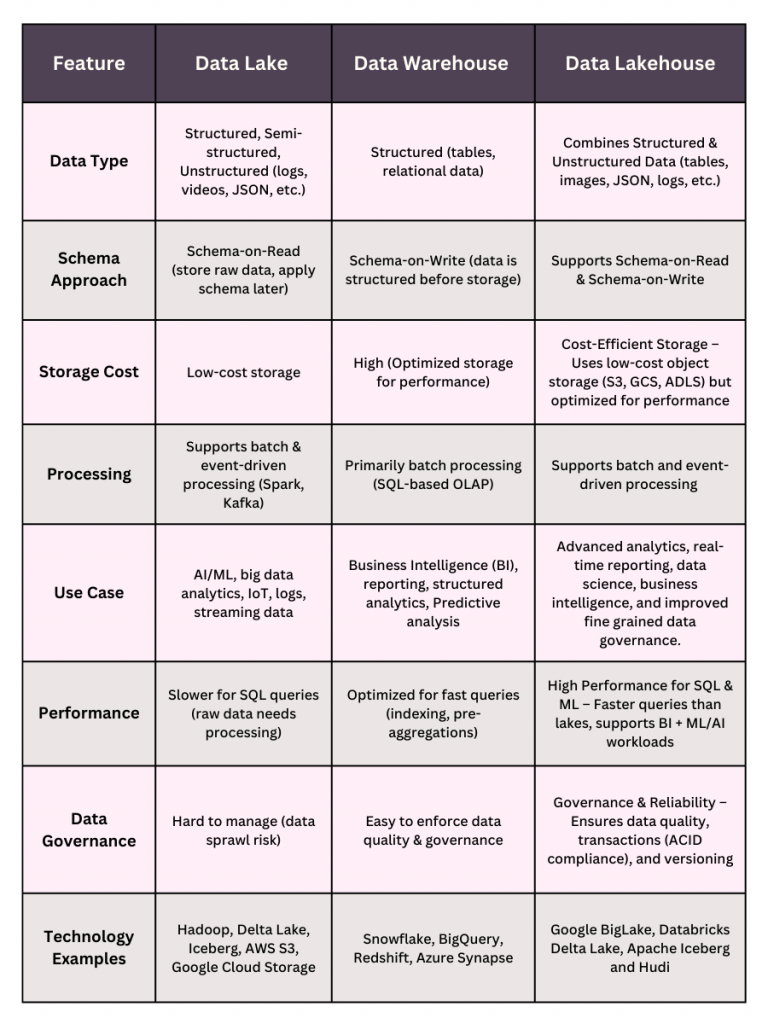
Table 1: Data Lake vs Data Lakehouse vs Data Warehouse: The Key Differences
Implementing Lakehouse in GCP
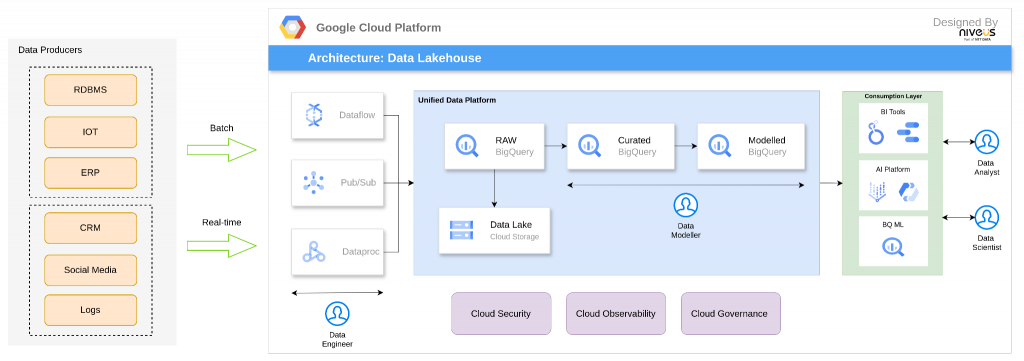
Image 2: Google Cloud Platform Data Lakehouse Architecture
Cloud Service Providers (CSPs) offer various solutions for building a lakehouse architecture, such as Databricks Delta Lake and Redshift Spectrum. As Data Lakehouse adoption continues to grow, the technology evolves to meet the increasing demand for scalable and efficient data management.
BigQuery remains one of the leading solutions for enterprise data management, capable of handling petabyte-scale workloads. With the introduction of BigLake, Google Cloud extends BigQuery’s architecture to align with Lakehouse principles. BigQuery also integrates seamlessly with Dataplex for unified data governance and Analytics Hub for data sharing across organizations. Dataplex, in particular, acts as a centralized data platform, supporting both Data Warehouse and Data Lake functionalities within Google Cloud.
Building a Data Lakehouse in Google Cloud
This involves 5 key aspects: ingestion, orchestration, data platform implementation, management, and operations. The data platform must integrate with multiple sources, accommodating both batch and streaming data ingestion. Google Cloud’s native tools, such as Pub/Sub and Dataflow, facilitate real-time data ingestion. Dataproc, a Hadoop-based service, is optimized for big data processing and transformations, particularly for machine learning (ML) and downstream analytics.
A well-structured data platform follows the medallion architecture, which consists of three layers:
- Storage Layer: The raw data landing zone consolidates data from multiple sources in different formats. This layer prioritizes low-cost storage while requiring further transformations.
- Curated Layer: The metadata layer where transformations are applied to enhance cost efficiency and performance. Best practices such as schema enforcement, caching, data masking, deduplication, and access control are implemented here.
- Modeled/Semantic Layer: This layer prepares data for downstream applications, including reporting, analytics, and business use cases. It enables structured aggregations concerning certain business functions and logic, supporting either “data as a product” or “data products”.
To ensure reliability and security, Google Cloud provides an extensive observability stack for monitoring platform health, usage, and access controls. Security mechanisms such as Identity and Access Management (IAM), data protection policies, compliance frameworks, and governance structures further enhance the data platform’s security.
Conclusion
The evolution from conventional databases to Data Warehouses, Data Lakes, and finally Data Lakehouses highlights the increasing demand for data solutions that are scalable, flexible, and cost-efficient. Data Lakes offers scalable storage for diverse data types, whereas Data Warehouse offers a structure and high-performance analytics. However, the Data Lakehouse strategy bridges the gap by combining the characteristics of both, ensuring unified data management with governance, cost-effectiveness, and performance optimization.
With the adoption of cloud-based solutions, platforms like Google BigQuery and BigLake enable enterprises to implement robust Lakehouse architectures, facilitating real-time analytics, machine learning, and AI-driven insights.
Modern enterprise data management is being revolutionized through the Data Lakehouse model which delivers a flexible, unified solution that accommodates traditional BI and advanced AI/ML workloads at an affordable price point and scalable infrastructure.
At Niveus Solutions A Part of NTT Data, we enable organizations with cutting-edge Data Lakehouse systems on Google Cloud, ensuring cost-effectiveness, seamless integration, and advanced analytics. By leveraging BigQuery, Dataplex, and AI-driven insights, Niveus helps organizations optimize data governance, real-time processing, and scalability.









