


The global multimodal AI market is witnessing exponential growth, projected to surge from USD 1.0 billion in 2023 to USD 4.5 billion by 2028, at a remarkable CAGR of 35.0%. Reflecting this momentum, Accenture’s 2023 Generative AI research reveals that 70% of business leaders are actively exploring or investing in Generative AI to drive innovation and boost organizational productivity. In this blog, we will look at the rapid rise of multimodal AI, its transformational potential in healthcare, and how models and agents are changing the landscape of diagnostics, patient treatment, personalization, and overall efficiency across the field.
Revolutionize healthcare with AI
Artificial Intelligence has continually evolved since its inception, advancing from its foundational beginnings to the remarkable capabilities it demonstrates today. AI has undergone a rapid transformation, progressing from solving traditional problems like basic arithmetic to addressing complex challenges that often elude human comprehension. This revolution has significantly impacted various industries, businesses, and revenue streams, thanks to AI’s enhanced computational power and learning capabilities. In this blog, we will explore the exponential growth of the AI market, delve into its evolution from its early stages to its current transformative capabilities, and highlight how AI is reshaping industries and driving innovation across the globe.
Since the early years when it was first attempted, from experimentation to expansion, which they called the golden year for AI when research saw a significant spike in AI’s progress, notable advancements occurred in areas such as problem-solving, natural language processing, and early neural networks. It was during this time that fundamental algorithms and theories were developed, leading to key innovations in the field.
Today, AI has become an integral part of work and daily life, continuously showcasing innovative capabilities. The most remarkable aspect is its iterative learning process, which has allowed us to witness the rapid rise of artificial intelligence. Its potential seems limitless, with its boundaries expanding endlessly, much like the universe itself.
Understanding Generative AI
Over the months, several foundational models have been developed, and humans have seen the smooth transition from Artificial Intelligence to Generative AI, which is built with multiple large language models to solve complex to advanced problems in any domain.
Generative AI has been trained with vast amounts of data, including globally and publicly available documents, research papers, and many more, so it can serve as an alternative to extensive research for a small topic.
Below is the architectural understanding of how machine learning works under the hood.
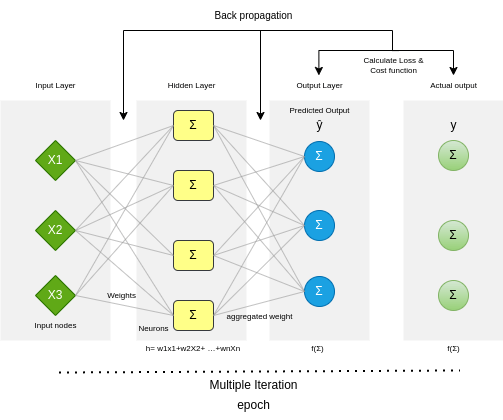
Figure 1: Machine learning under the hood
State of Generative AI
Exposure to generative AI has been introduced by several researchers, data scientists, and business owners to enhance their impact in their roles. AI is now publicly accessible through various interfaces, including GPT-3’s OpenAI, Google’s Gemini, and numerous open-source models. These LLMs are widely adopted by users and are capable of providing complex responses, engaging in conversations, and generating code. They address numerous global challenges by mimicking human behaviour and leveraging task automation, which can pave the way for Robotic Process Automation (RPA).
Business users are openly leveraging AI / GPT to boost their productivity, improve decision-making, content generation, and as an alternative to human manual operations, which are quite time-consuming.
Many legacy applications and software vendors are now integrating LLMs into their systems to seamlessly incorporate AI, driving a shift from traditional workflows within CRMs, enterprise platforms, and beyond.
How the transformation of Gen AI evolved to solve more complex problems:
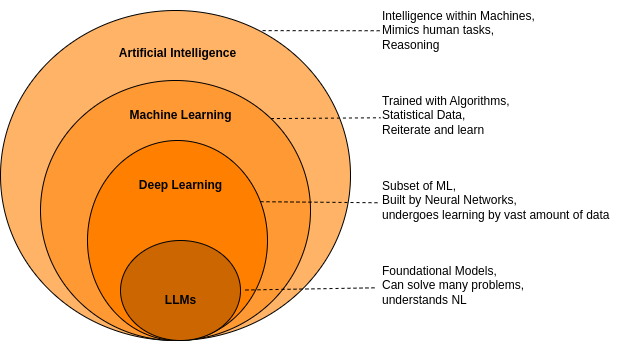
Figure 2: Where does LLM stand
Let’s take a few scenarios in context. Suppose there is a marketing manager, who is responsible for generating media content, sharing, distributing and collaborating with other media channels You can also consider a developer who is responsible for scripting & programming to build responsive visual interfaces, or a data analyst who wants to fetch data, aggregate and perform business analytics using SQL. Throw in an app developer looking to create health care chatbots for his specific domain. Now, imagine if all of these tasks were handled by one person. That’s Generative AI. Generative AI can perform all these tasks as it is considered a unified service.
To generate results, generative AI processes responses based on requests and its foundational learning. It has been trained on vast datasets, with an extensive number of parameters and hyperparameters, all supported by immense computational power.
Going from traditional models to foundation models, it has been introduced with “Transformers” in 2017, which is a type of artificial intelligence and additional neural network architecture type acts as a learning growth catalyst, where it helps the researchers to implement even large models by training with billions of data and to get in-depth responses for a query. It is designed to handle sequential data mainly to do language translation, code generation, logical reasoning, and many more automation.
Transformers were then introduced to a term called “Attention,” which gathers the combination and connection with different entities. Attention assigns the weights to each input parameter so the model prioritizes the information to retrieve and connect with other references. While they are not just restricted to analyzing the information or weights, they are flexible enough to build a relation and track to analyze the segment of code, threat events data, depth information of Physics, chemicals, and many more.
It has grown even more, from Large language models(LLMs) of Generative AI to Artificial General Intelligence(AGI), which has led to innovations that can handle multimodal processing, which now enables users with different types of prompts. Primary Foundation models now include Open AI’s Dall-E, Claude 3 by Anthropic, Google’s Gemini for Multimodal processing, including Gemma, a few lightweight models like Codey for code generation, Imagen 3 for image generation, and Janus Pro from Deepseek, which was quite recently launched by a Chinese Startup.
These models come with compatibility to use for general purposes or to serve a certain task by fine-tuning the models, which are very specific to one domain or industry, depending on the use case requirements.
How Multimodal AI Works
Whether it’s a traditional AI model or a multimodal LLM, the workflow remains consistent and follows the key aspects outlined below:
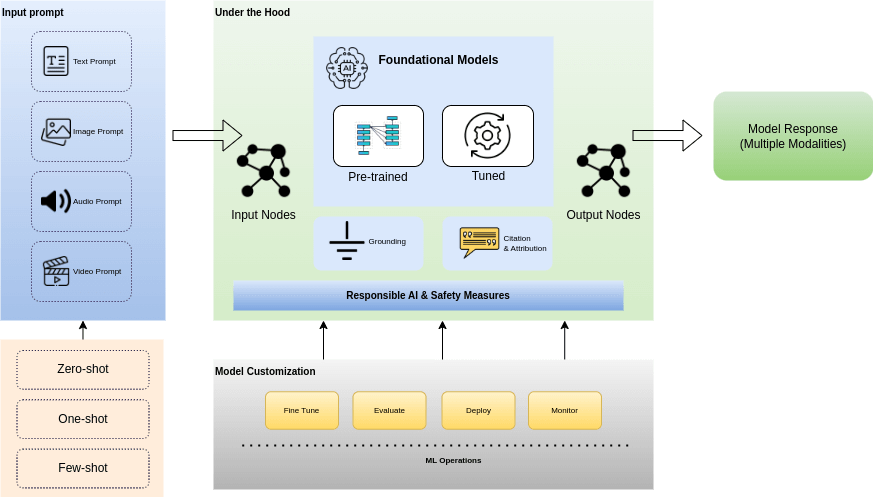
Figure 3: Multimodal AI – high-level architecture
- Input prompt: The input request that has been provided to the model using natural language, which can be of different modalities(text, image, audio, or video).
- Responsible AI and safety Measures: The model undergoes certain responsible and safety checks, which adhere to certain principles and ethics that have been set.
- Foundational Models: The request will be processed by certain foundation models (like GPT, Gemini, and Imagen) and the best-fit model based on the need and inputs given by the user.
- Model customizations: Users are flexible enough to customize the models based on their specific needs, either by fine-tuning or training with their dataset.
- Results Grounding: The results undergo certain checks by the grounding mechanism, which tries to make a connection with the variables set and to have factual accuracy and contextuality to avoid any hallucinations, also undergo Citations to validate data trust in the model’s response and ensure its credibility
- Final response: The results given by the model in natural language, based on the request, can also be in different modalities.
So let’s explore the capabilities of Multimodal AI and delve deeper into the practical impact on both fundamental and functional aspects.
As its name suggests, Multimodal deals with multiple modalities. Multimodal AI is a large foundational model to process the information that is in multiple data types, such as text, images, audio, and video. The output generated by AI can also be considered to have multiple modalities, whereas an unimodal output deals with only one data type.
Multi-modal AI adds a layer to generative AI to make it more powerful by having capabilities to manage multiple types of data in inputs and outputs. As mentioned earlier, OpenAI’s Dall-E leads to the foundational tech stack for multimodal systems, where GPT-4 has been implemented in ChatGPT as well.
At its core, Multimodal AI can be utilized to generate captions describing images sent to the model, such as an image of a mountain, or to analyze an image containing ingredients and provide a recipe based on those ingredients.
In summary, Multimodal models can help with multiple use cases such as data extraction, data analysis, data analytics, data conversion, information seeking(Q&A), content creation like media and posters, and media analysis.
How do these Multimodal AIs work
We have gone through the context of the unimodal, where it can solve many complex problems, but only deals with a single data type(single modality). If we take the example of GPT-3, it is a text-to-text model that fails to interpret images or also to generate images.
Multimodal has a 3-layered architecture:
- Input Module: As we have already understood, multimodal is an additional layer to the unimodal, hence, it is encompassed with multiple unimodal neural networks, making this the input to the module, which is expected to get multiple data types as input.
- Fusion Module: Fusion models combine the data from the input, collate it, and process it by concatenating various raw data.
- The Output Module: Is the final response or results from the model, which again depends on the complexity of the underlying inputs and use case.
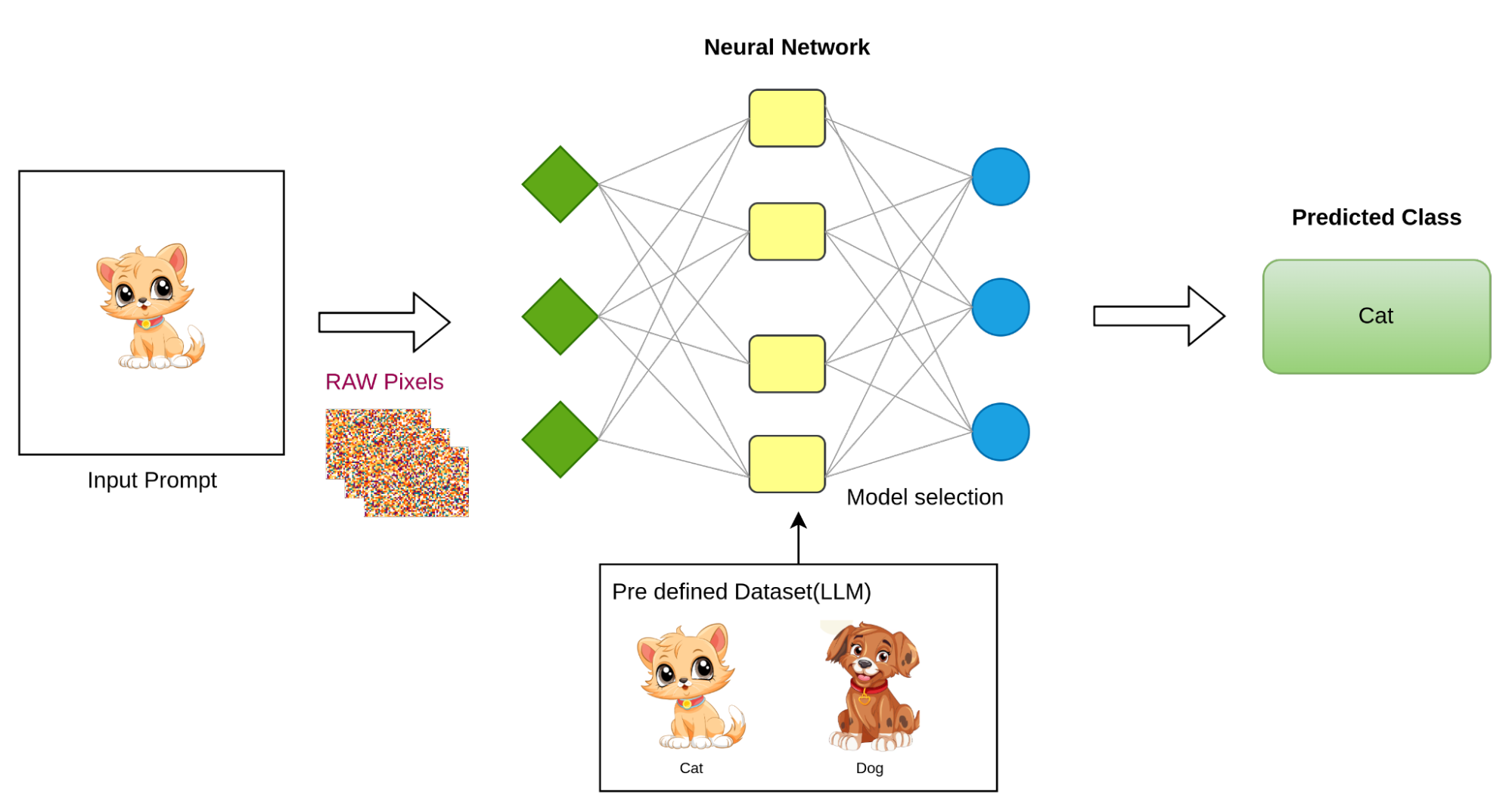
Figure 4: Image Classification Model(LLM)
Now let’s take a look at the above image to understand how these multimodal AIs work at a high level. The image explains the Image-to-text model.
Consider the commonly used example of a cat. Suppose the model is prompted with a clip art image of a cat as input. The model has been trained on a large dataset containing labelled examples of cats and dogs. The task is to assign the correct label class to the given input, which, in this case, is a classification problem (Image classification).
The challenge is that images cannot be directly fed into the model, as computers are unable to process raw image data in the same way they handle numeric inputs. However, images consist of pixels, which are essentially numeric data. Each image has fixed dimensions (height and width) and contains three colour channels (RGB). These numerical representations of the pixels are what the model can process for analysis.
According to the statistics, the average pixel density in an image is typically around 72 pixels per inch, though it can vary depending on the quality and dimensions of the image. Based on Shutterstock data, social media images generally have a resolution of 1080×1080 pixels.
Now the model has to build the relationship between raw pixels and the class label according to the training dataset that has been provided, and this task is trivial and challenging for an ML model to relate, and identify the pattern according to the pixel data, since the model has to observe each pixel thoroughly, but the LLM contains a massive amount of of computational power and faster execution due to its ability where human cannot make such minute tasks which is next to impossible.
In conclusion, machine learning operates by starting from scratch and gradually building connections by identifying relationships between the input data and the corresponding labels.
For part 2 of this blog, we will explore multi-modal AIs in depth. We will look at prompt designs, types of Multimodal AI, and how multimodal AI is transforming applications in healthcare. Additionally, we will have a look at the challenges of taking multimodal AI systems from experimentation to practice, as well as highlighting the real-world use cases of multimodal AI.









