


Enterprise AI systems that rely solely on GenAI can experience latency of 3–5 seconds per query, while hybrid architectures achieve sub-500ms response times for 70% of interactions by routing to deterministic systems. However, building this performance advantage requires sophisticated query classification, confidence-based routing logic, and graceful degradation patterns that prevent the system from failing when primary execution paths fall short. Part 2 of this blog explores how to operationalize hybrid AI architectures by building a resilient routing layer, designing robust fallback mechanisms, and enabling a data layer that supports both real-time decisioning and contextual reasoning.
Transform hybrid AI from concept to production.
The gap between the hybrid AI promise and production reality is wide. Organizations understand the value proposition, but translating this into a working infrastructure exposes critical design questions. How should routing logic balance speed and accuracy when confidence scores fall into ambiguous ranges? What fallback sequence ensures continuity when the primary execution path fails? How can real-time data feed both rule engines requiring sub-500ms responses and GenAI models needing rich contextual grounding?
These obstacles prevent most hybrid implementations from achieving the 70/30 routing distribution and 50–100x cost efficiency cited in industry benchmarks. Success requires deliberate architectural choices across three interdependent layers: intelligent routing infrastructure, resilient fallback mechanisms, and unified data architecture.
Technical Implementation Guide
This section outlines how to operationalize a hybrid AI architecture by combining deterministic systems with Generative AI. The focus is on building a resilient routing layer, designing robust fallback mechanisms, and enabling a data layer that supports both real-time decisioning and contextual reasoning.
A. Building the Routing Layer
The routing layer is the control plane of the hybrid architecture. Its primary responsibility is to evaluate each incoming request and determine the most appropriate execution path, rule-based, GenAI-driven, or a hybrid of both, based on intent, complexity, and confidence.
1. Query Classification
Query classification establishes the foundation for intelligent routing. Each request is evaluated across multiple dimensions:
- Intent classification: Identifies whether the query maps to known deterministic use cases such as fare validation, booking status, policy lookup, or refund eligibility.
- Complexity scoring: Assesses linguistic ambiguity, number of entities involved, dependency on historical or contextual data, and need for reasoning.
- Entity completeness: Determines whether all mandatory parameters required for deterministic execution are present.
A simplified routing logic is illustrated below:
# Pseudocode for routing logic
def route_query(user_input)
intent = classify_intent(user_input)
complexity = calculate_complexity(user_input)
if intent in DETERMINISTIC_INTENTS and complexity < THRESHOLD:
return "RULE_ENGINE"
elif has_required_entities(user_input):
return "HYBRID_SEQUENTIAL"
else:
return "GENAI_LAYER"In production environments, this logic is typically implemented using a combination of lightweight ML classifiers, heuristics, and rule-based decision trees deployed via Cloud Functions or Cloud Run for low-latency execution.
2. Confidence-Based Fallback
Routing decisions should not be binary; they must be probabilistic and confidence-aware.
Key implementation considerations include:
- Confidence thresholds: For example, deterministic execution may require a minimum confidence score of 0.85 from the intent classifier.
- Graceful degradation: If confidence drops below the threshold mid-execution, the system should degrade to a hybrid or GenAI path rather than failing outright.
- Decision observability: Every routing decision should be logged with intent, confidence score, execution path, and outcome for downstream analysis.
This enables continuous tuning of routing logic based on real-world performance rather than static assumptions.
B. Designing Fallback Mechanisms
Fallback mechanisms ensure reliability, accuracy, and continuity of the user experience when primary execution paths fail or produce suboptimal results.
1. Types of Fallback
A mature hybrid system typically supports multiple fallback modes:
- Hard Fallback: Triggered when the rule engine cannot execute due to missing data, unsupported intent, or system errors. Control is fully handed off to the GenAI layer.
- Soft Fallback: Used when deterministic execution succeeds but provides a minimal or rigid response. GenAI augments the output with explanations, recommendations, or conversational framing.
- Validation Fallback: If GenAI output fails schema validation, policy constraints, or compliance checks, the system re-routes to deterministic logic or returns a constrained response.
This layered fallback approach balances flexibility with control.
2. Error Handling Patterns
Robust error handling is critical for enterprise-grade deployments:
- Timeout management
- Rule layer: ~500 ms (strict SLA-driven execution)
- GenAI layer: up to 5 seconds (to accommodate reasoning and retrieval)
- Retry logic: Recoverable errors should trigger retries with exponential backoff and, where applicable, modified prompts or reduced context.
- Circuit breakers: Prevent cascading failures by temporarily disabling unstable services and forcing alternate execution paths.
These patterns are typically implemented using service meshes, API gateways, or custom middleware.
3. Fallback Decision Trees
A representative decision flow for deterministic execution may look like:
Rule Engine Execution
├── Success (70%)
│ ├── High confidence → Direct response
│ └── Medium confidence → GenAI enhancement
└── Failure (30%)
├── Recoverable error → Retry with modified input
└── Non-recoverable → Full GenAI fallbackThis structure allows systems to maximize deterministic efficiency while retaining GenAI flexibility for edge cases.
C. Data Layer Architecture
The data layer underpins both deterministic logic and GenAI reasoning. It must support low-latency transactional access as well as rich contextual retrieval.
1. Real-Time Data Integration
Key characteristics include:
- Streaming ingestion from core systems (e.g., booking, claims, CRM)
- Event-driven updates using Pub/Sub to propagate state changes
- Optimized access patterns to support sub-second reads for rule execution
This ensures that both layers operate on consistent, near-real-time data.
2. Knowledge Base Management
For GenAI-driven reasoning, knowledge management is critical:
- Policy document versioning to ensure traceability and auditability
- Vertex AI Search indexing strategies optimized for semantic retrieval and scoped grounding
- Update propagation mechanisms to ensure changes in policies or rules are reflected immediately in GenAI responses
Tight coupling between knowledge updates and retrieval indices reduces the risk of hallucinations.
3. Monitoring & Observability
End-to-end visibility is essential for operating hybrid AI systems at scale:
- Cloud Trace for visualizing request flows across routing, rule, and GenAI layers
- Cloud Logging for capturing decision points, confidence scores, and fallback triggers
- Custom metrics to track routing distribution, latency, accuracy, and cost per request
These signals enable proactive optimization and governance.
Best Practices & Design Considerations
A. When to Choose Each Pattern
A value complexity matrix is an effective decision framework:
- High value, low complexity: Deterministic execution
High value, high complexity: Hybrid (rule-first or GenAI-assisted) - Low value, high complexity: GenAI-only, if ROI is justified
This prevents overuse of GenAI where deterministic logic is sufficient.
B. Cost Optimization
Cost discipline is a core driver of hybrid architectures:
- Rule layer cost: Approximately $0.001 per query
- GenAI layer cost: Approximately $0.05–$0.10 per query
A well-optimized system typically routes ~70% of queries to deterministic paths and ~30% to GenAI, delivering significant cost savings without sacrificing experience.
C. Security & Compliance
Security must be enforced consistently across both layers:
- Unified data governance policies for deterministic and GenAI systems
Strict PII handling, including masking, tokenization, and access controls - Audit-ready logging and traceability for regulatory compliance
By designing security as a shared concern rather than a layer-specific feature, organizations can safely scale hybrid AI systems in regulated environments.
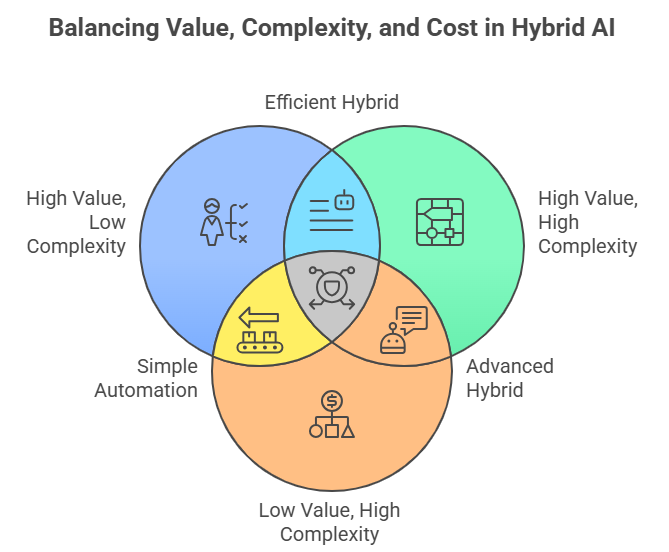
Figure 1: Visual illustration of Best Practices & Design Considerations: When to Choose Each Pattern, Cost Optimization, Security & Compliance
Conclusion
Hybrid AI architectures achieve both innovation and reliability by routing 70% of queries through deterministic systems and reserving GenAI for complex edge cases. This approach delivers sub-500ms response times and 50–100x cost efficiency while maintaining zero-error precision for regulated environments.
Success depends on three core components: intelligent routing with confidence-aware classification, layered fallback mechanisms that degrade gracefully, and unified data architecture serving both transactional and semantic needs. Organizations that build these foundations deliberately can scale GenAI in production without compromising operational reliability.
To see how these principles apply in production environments, explore our whitepaper for detailed guidance on use-case identification, hybrid decision frameworks, persona-driven applications, and leveraging Google Cloud’s AI stack for secure, scalable enterprise deployment.









