


According to reports, global data production, sharing, and storage is expected to surpass 175 zettabytes by 2025. For modern businesses, this data explosion is a growing burden as well as a treasure trove. Critical systems still use structured databases for data storage. However, system performance is determined by how easily we can access the data, especially with SQL. In this blog, we’ll explore what SQL does, why good query design matters, and the 6 SQL best practices to help you write clean, fast, and scalable SQL.
Start writing smarter SQL
Picture a table with 10 million rows. Now, think about running a query that looks at each one of those rows sequentially to find a small set of records. Not a single index. No filters. Simply using force. Multiply that by thousands of users and your blazingly fast application suddenly becomes slow, costly, and prone to crashes. Poorly written queries are one of the top culprits behind slow response times, rising infrastructure costs, and unreadable code. That’s where smart SQL practices come in.
Optimizing SQL: Balancing Speed, Scale, and Cost in Data Applications
Over 90% of the world’s data was generated in the last two years, with a significant portion residing in structured databases. Organizations are reliant on structured data to power their data-driven apps. SQL, a standardized programming language, is a powerful tool in modern data processing for both heavy analytics and basic reports. With that context in place, let’s dive straight into some of the SQL best practices and SQL query optimization techniques that can help you write cleaner queries, optimize performance, and ensure scalability for enterprise-grade applications.
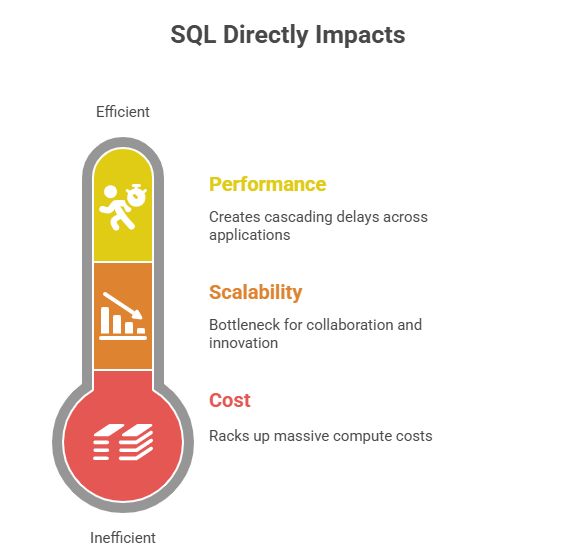
Fig 1: SQL Direct Impact
Efficient SQL isn’t just about aesthetics, it directly impacts:
- Performance: Slow queries lock up resources and create cascading delays across apps and dashboards.
- Scalability: As teams and datasets grow, poorly structured SQL becomes a bottleneck for collaboration and innovation.
- Cost: On cloud platforms like BigQuery, Redshift, or Snowflake, inefficient queries can rack up massive compute costs.
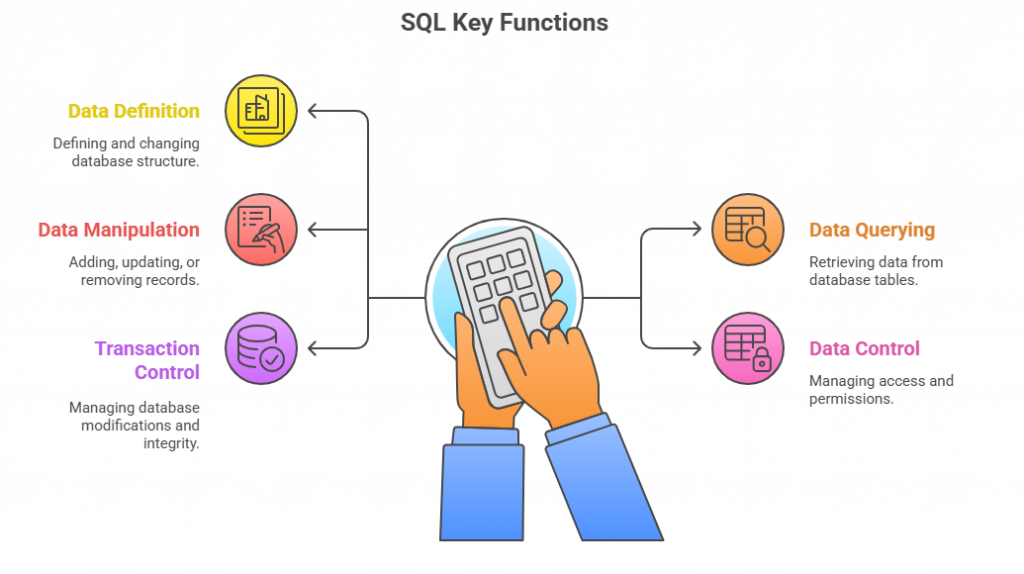
Fig 2: Different functions of SQL
Common Anti-Patterns and Their Best-Practice Alternatives
Let’s break down some common mistakes developers make and the best practices that can turn those slow, error-prone queries into efficient, maintainable SQL.
1. SELECT * vs Explicit Columns
Anti-Pattern:
SELECT * FROM customer c
JOIN order o ON c.customer_id = o.customer_id
WHERE c.name = 'John Doe';- Pulls unnecessary columns
- Increases I/O and network overhead
- Breaks when schema changes
Best Practice:
SELECT c.customer_id, c.name, c.email,
o.order_id, o.order_date, o.amount
FROM customer c
JOIN order o ON c.customer_id = o.customer_id
WHERE c.name = 'John Doe';- Improves performance, readability, and schema resilience.
Why this matters: Using SELECT * may seem convenient, but it often strains system resources, increases query costs on cloud databases, and makes downstream processes brittle. It also increases memory use during sorts and joins. Explicit column selection avoids these pitfalls and improves long-term maintainability (StackOverflow, Medium).
2. Using DISTINCT vs GROUP BY
Anti-Pattern:
SELECT DISTINCT product_id, customer_id
FROM sales;- Deduplicates after fetching all rows
- Adds unnecessary sorting overhead
Best Practice:
SELECT product_id, customer_id
FROM sales
GROUP BY product_id, customer_id;- Improves performance, adds clarity, and reflects intent.
Why this matters: DISTINCT works as a post-processing step that forces the database to sort and eliminate duplicates after scanning all rows. GROUP BY is generally more efficient since it organizes rows during processing and clarifies intent (SQLShack).
3. COUNT vs EXISTS
Anti-Pattern:
SELECT c.customer_id, c.name
FROM customer c
WHERE (SELECT COUNT(*)
FROM order o
WHERE o.customer_id = c.customer_id) > 0;- Computes full counts for all customers
- Wastes compute cycles
Best Practice:
SELECT c.customer_id, c.name
FROM customer c
WHERE EXISTS (
SELECT 1
FROM order o
WHERE o.customer_id = c.customer_id
);- Stops scanning on the first match, saving resources.
Why this matters: COUNT(*) needs to count every matching row, even if only one is needed, whereas EXISTS stops after the first match. Benchmarks show EXISTS can be many times faster, especially on large datasets (jOOQ Blog, RedGate).
4. Avoiding <> with Indexed Columns
Anti-Pattern:
SELECT order_id, customer_id, amount
FROM order
WHERE status <> 'Completed';- Prevents index usage
- Forces full table scan
Best Practice:
SELECT order_id, customer_id, amount
FROM order
WHERE status IN ('Pending', 'Shipped', 'Cancelled');- Uses indexes effectively and avoids expensive scans.
Why this matters: Comparisons with <> or applying functions on indexed columns are not SARGable (Search ARGument-able), meaning the database cannot use indexes effectively. This forces full table scans and increases CPU and I/O load (Brent Ozar).
5. UNION vs UNION ALL
Anti-Pattern:
SELECT order_id, customer_id, order_date, amount
FROM online_order
UNION
SELECT order_id, customer_id, order_date, amount
FROM in_store_order;- Removes duplicates by default
- Adds unnecessary sorting overhead
Best Practice:
SELECT order_id, customer_id, order_date, amount
FROM online_order
UNION ALL
SELECT order_id, customer_id, order_date, amount
FROM in_store_order;- Avoids sorting when duplicates are not expected.
Why this matters: UNION implicitly deduplicates results, requiring expensive sorting or hashing. If duplicates are not possible or not relevant, UNION ALL avoids this overhead and performs significantly better (StackOverflow).
6. LIKE with Leading Wildcards vs Optimizable Patterns
Anti-Pattern:
SELECT * FROM customers WHERE name LIKE '%son%';- Prevents index usage
- Forces full table scan
Best Practice:
SELECT * FROM customers WHERE name LIKE 'son%';Why this matters: Leading wildcards (%abc) make indexes useless since the database cannot predict where to start scanning. Optimizing with anchored patterns (abc%) or using full-text indexes improves search performance dramatically (Use the Index, Luke).
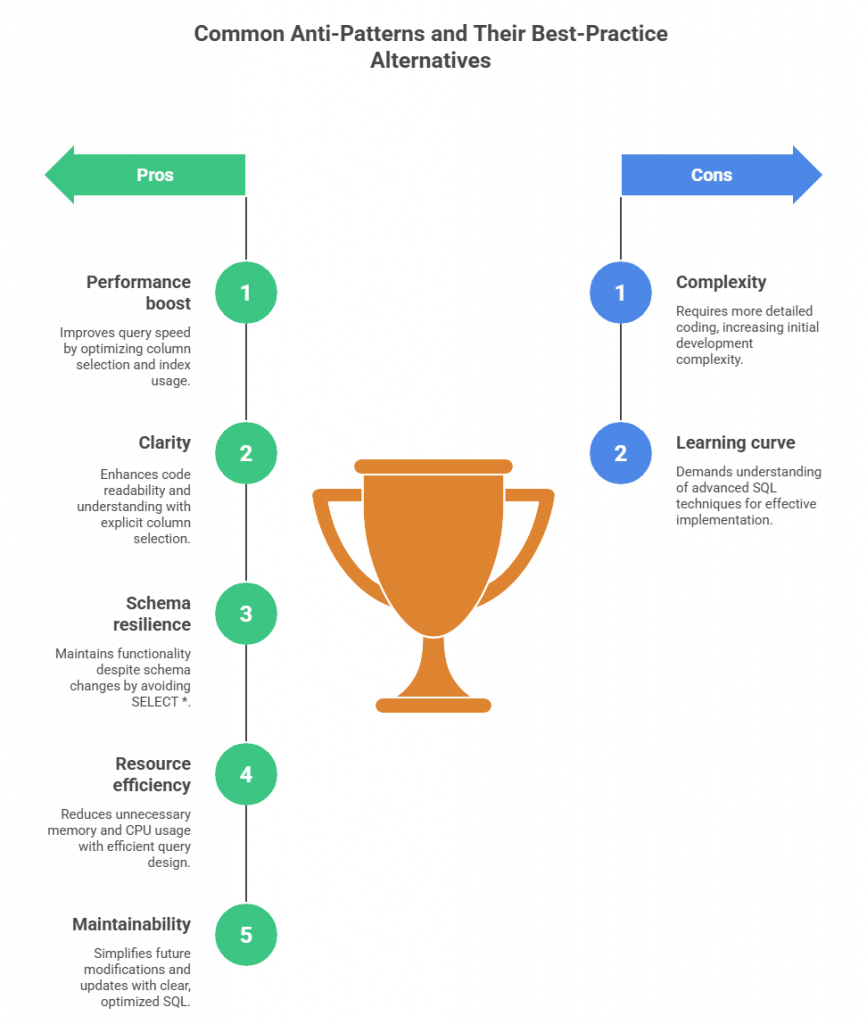
Fig 3: Illustration showing the pros (performance, clarity, resilience, efficiency, maintainability) and cons (complexity, learning curve) of SQL best practices.
Beyond Queries: Database Design & Operational Best Practices
While query structure is critical, the foundation of SQL best practices lies in strong database design and efficient operations. Solid design ensures that SQL query optimization techniques have maximum impact:
- Indexes: Use them wisely, focus on columns in frequent filters/joins. Avoid over-indexing as it slows writes.
- Data Types: Pick types that reflect the data (e.g., don’t use VARCHAR for dates/numbers). This improves both performance and storage.
- Partitioning: For large datasets, use horizontal partitioning/sharding or vertical partitioning for rarely accessed columns.
- Normalization: Normalize up to 3NF for consistency, but de-normalize selectively for performance-critical reporting tables.
- Monitoring & Alerts: Track query performance, deadlocks, and storage use. Use EXPLAIN plans before deploying heavy queries.
- Caching: For frequently accessed data, caching can reduce load on primary databases.
- Governance: Version control for DDL changes, proper documentation, and integrity constraints (PK, FK, CHECK) ensure long-term maintainability.
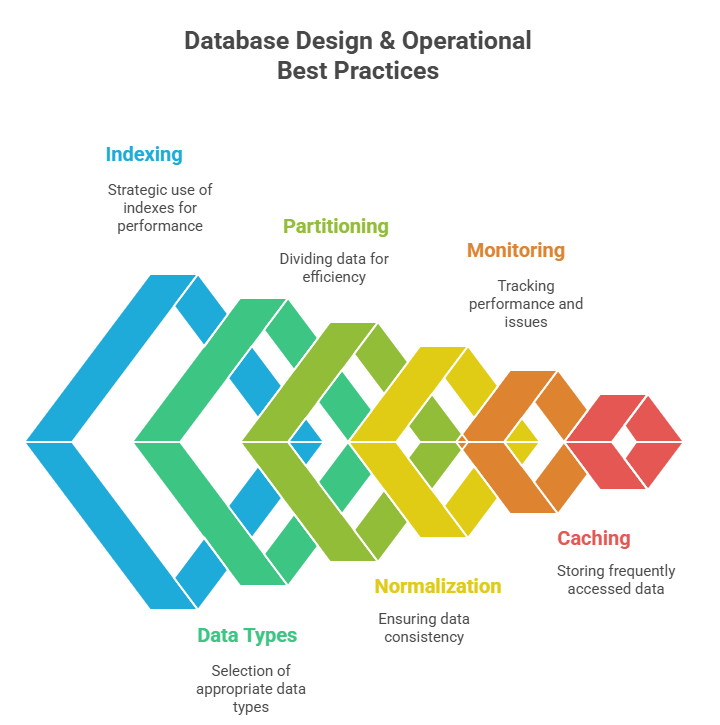
Fig 4: Database Design & Operational Best Practices
Why SQL Best Practices Matter in the Enterprise
For enterprises, SQL best practices are not just about writing clean queries; they are about operational efficiency, scalability, and reliability:
- Cost Management: Inefficient queries in cloud-native warehouses directly impact bills.
- Collaboration: Consistent, readable SQL helps teams debug faster and scale knowledge sharing.
- Resilience: Proper indexing, caching, and partitioning ensure systems remain reliable, even under heavy load.
How Niveus Applies SQL Best Practices
Niveus Solutions – part of NTT DATA is leveraging SQL to power everything from the latest data platforms to transactional enterprise applications. Some real-life examples are:
- Modern Data Platforms: BigQuery and Snowflake SQL pipelines enable scaling out the data warehouse beneath all of it.
- Business Intelligence (BI): Reusable SQL queries are responsible for the Looker and Tableau dashboards steering real-time reporting.
- ETL Pipelines: Conventional SQL transformations (via debt, Dataform) provide transparency and tractability, with negligible barriers to maintainability.
- Data-Driven Applications: From BFSI to retail, SQL best practices keep codebases lean and fast in transactional systems.
- Cloud-Native Innovation: As a Google Cloud Premier partner, Niveus is able to leverage SQL in conjunction with Vertex AI and BigQuery ML to reconcile source analytics workloads and machine learning workloads.
Case Study
Seamless Cloud Migration & Disaster Recovery with Niveus: Niveus collaborated with Craft Silicon, a worldwide financial firm, to move its on-premises infrastructure to Google Cloud Platform (GCP), deployed within three weeks and with zero downtime. The move entailed creating a new GCP environment to host their applications and MS SQL databases, optimizing their SQL processes. To provide business continuity and resilience, a full disaster recovery (DR) solution was also created, replicating databases from the on-premises data center to a different GCP region.
Conclusion
From backend systems and analytics dashboards to AI-powered cloud workloads, SQL remains the universal language of structured data. Effective SQL writing is a business need, not simply a developer’s ability.
By avoiding common pitfalls, adopting SQL best practices, and applying consistent SQL query optimization strategies, organizations can unlock faster performance, lower costs, and build scalable systems that will stand the test of time.
Whether you’re creating your first query or optimizing a complicated pipeline, remember that clever SQL is the foundation of smart systems.









