


Industry studies estimate that enterprise downtime costs ~$5,600 per minute, with nearly 40% of large organizations experiencing outages longer than four hours, highlighting the high cost of a fragile IT system. At the core of any resilience cloud strategy is a deceptively simple but critical question: which region should serve as your disaster recovery (DR) site? The answer directly impacts recovery objectives, regulatory compliance, and operational costs, yet it’s often decided late or reduced to a cost-driven afterthought. In this blog, we break down the five critical factors that should guide your GCP DR region selection and protect your business from prolonged downtime.
Strategic regions prevent costly downtime.
The gap between inevitable disruption and controllable impact is where disaster recovery decisions matter the most. When outages extend beyond minutes, the difference between rapid recovery and prolonged downtime lies in early, foundational choices, not the technology itself. Selecting a DR region is therefore a strategic decision that directly shapes business continuity, compliance, and long-term resilience.
Why Disaster Recovery Region Selection Is No Longer Optional
Today’s enterprises face a spectrum of threats, ranging from regional outages and natural disasters to cyberattacks and compliance violations. According to global IT resilience benchmarks, 15% of outages extend beyond 24 hours. In such cases, the financial and reputational damage can be staggering (Refer to Fig 1).
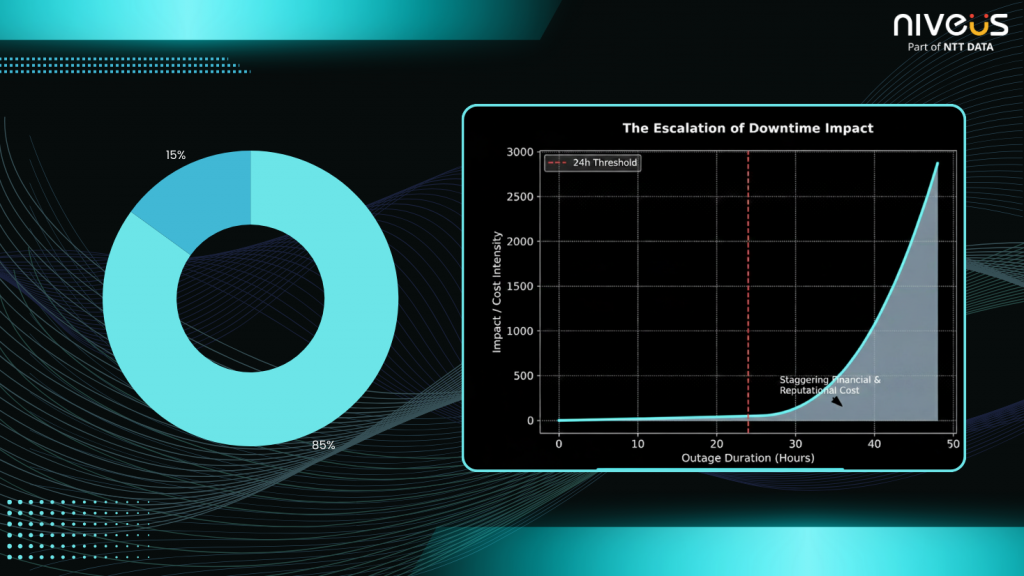
Fig 1: Prolonged outages sharply escalate financial and reputational impact, making disaster recovery region selection a business-critical decision.
Moreover, disaster recovery decisions are shaped not only by infrastructure geography but also by several operational and legal constraints, including:
- Latency and replication limits imposed by physical distance
- Compliance and data residency laws
- Regulatory frameworks across jurisdictions
- Network and operational costs
Consequently, a tactical region choice made without strategic alignment can cause even well-designed DR architectures to fail under real stress.
A Data-Driven Framework for Choosing Your GCP DR Region
To make disciplined decisions, we advocate a five-factor framework that every enterprise should apply before committing to a DR region on Google Cloud:
1. Geographic Diversity: The Foundation of Resilience
Distance isn’t just a number; it’s a measure of risk separation.
Best practice guidelines recommend a minimum separation of 300–500 km between primary and secondary sites to avoid correlated outages (Refer Fig 2). For Indian and Asia-Pacific enterprises, common GCP region pairs include:
- Mumbai ↔ Delhi: ~1,400 km separation
- Mumbai ↔ Singapore: ~4,000 km separation
- Mumbai ↔ Sydney: ~10,000 km separation

Fig 2: Visual illustration of GCP primary-to-DR region distances versus the minimum recommended 500km separation threshold.
These distances matter because they determine exposure to regional weather events, power grid failures, and geopolitical disruptions. While closer regions reduce latency, they often share national risk domains. Therefore, regulated enterprises must evaluate this trade-off carefully before committing to in-country DR pairings.
2. Network Latency: The Physics of Replication
Latency isn’t an abstract metric; it directly governs what kind of replication you can achieve (Refer Fig 3). Measured Round-Trip Times (RTT) between regions correlate with practical replication modes:
- <10 ms RTT: Synchronous replication (RPO near zero)
- 10–50 ms RTT: Near-synchronous replication (RPO <15 min)
- >50 ms RTT: Asynchronous only (RPO ≥30 min)
Real-world latency data shows:
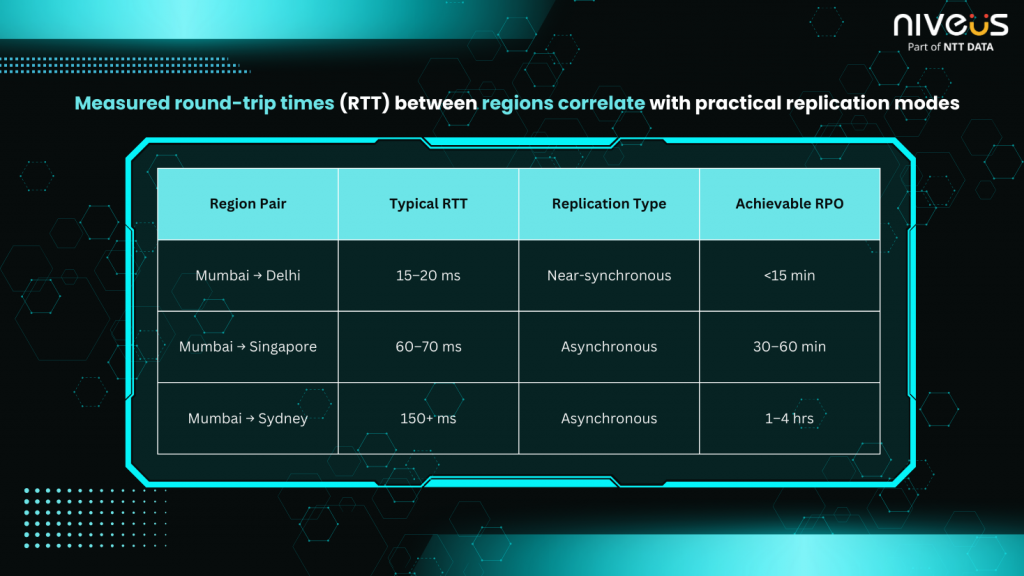
Fig 3: Visual illustration of how network latency between regions determines feasible replication modes and achievable RPO targets.
The implication is clear: Because physical separation influences latency, it directly shapes replication feasibility. Without this understanding, even well-designed DR plans become paper exercises in a real incident.
3. Compliance & Data Residency: Hard Constraints, Not Afterthoughts
Regulatory obligations can eliminate options before cost or performance even enters the discussion. For example:
- India’s central bank (RBI) mandates that certain categories of financial data remain within Indian jurisdictions.
- Healthcare data frequently requires in-country residency and strict privacy safeguards.
- Emerging data protection regimes increasingly restrict cross-border replication.
If compliance requirements are not validated during the DR design phase, enterprises often face forced migrations later. Such mid-project corrections can take 4–6 months and cost up to three times the original implementation budget. Therefore, regional choice must be treated as a legal and strategic decision, not merely a technical one (Refer Fig 4).
Therefore, regional choice must be treated as a legal and strategic decision, not just a technical one.
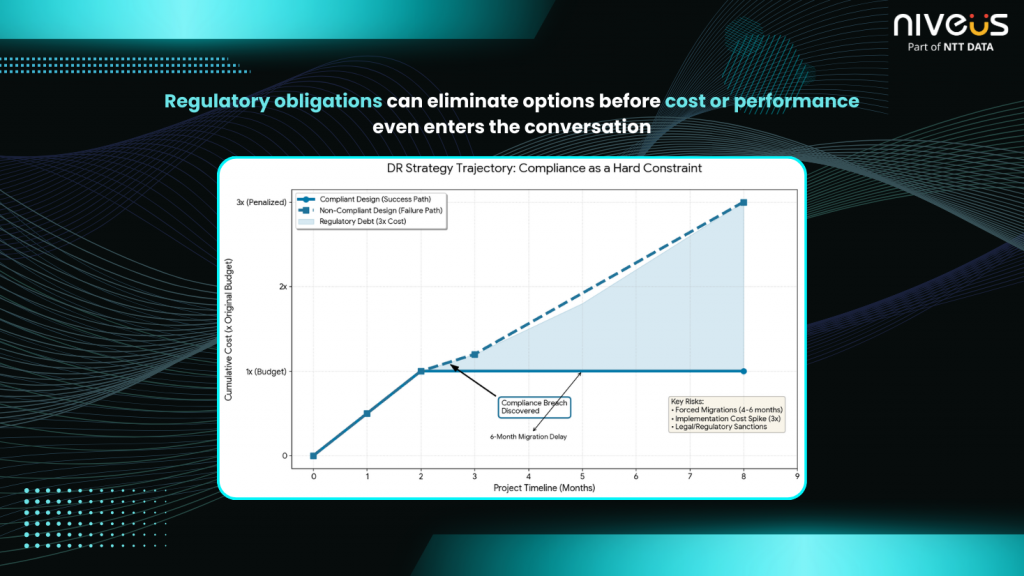
Fig 4: Visual illustration of DR strategy cost trajectory when compliance requirements are introduced as hard constraints mid-project.
4. RTO/RPO Requirements: Managing Expectations with Reality
Recovery targets must align with what architecture can realistically deliver. Mission-critical applications with RTO <1 hour and RPO <15 minutes require low-latency replication, which is typically achievable only between geographically closer regions. By contrast, business-critical workloads can tolerate longer RPO windows, enabling broader geographic separation at higher latency.
However, practical recoveries depend on more than replication speed alone. Failover orchestration, DNS propagation, application initialization, and validation testing all contribute to total recovery time (Refer Fig 5). Even with a warm DR setup, cross-region failover can consume 40–60 minutes unless specifically engineered for speed.
For this reason, allowing a 30–40% buffer above stated RTO objectives helps ensure targets are met under real-world conditions.
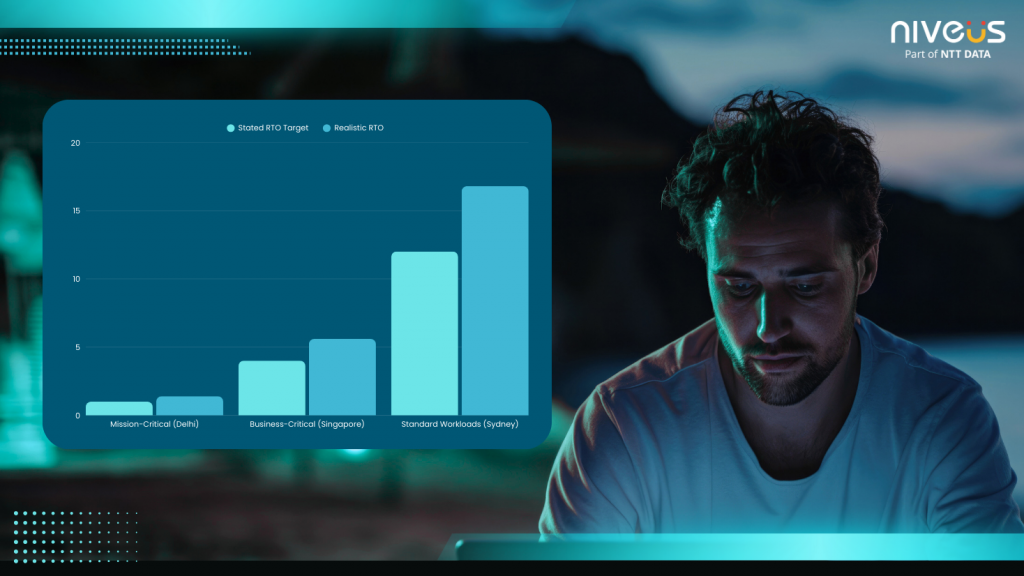
Fig 5: Visual illustration of the gap between stated RTO targets and the realistic RTO achievable based on workload criticality and geographic distance.
5. Cost: More Than Just Compute
DR costs are frequently underestimated because pricing appears straightforward until replication begins at scale. Although compute and storage pricing vary modestly by region, network egress charges often dominate the total cost of ownership (TCO).
For example:
- Intra-region replication: ~$0.05/GB
- Inter-Asia replication: ~$0.08/GB
- Inter-continental replication: ~$0.12–0.23/GB
For a workload generating 500 GB of daily data changes, the financial impact becomes material over time. Consequently, network egress often emerges as the largest recurring DR cost driver, particularly for data-intensive environments (Refer Fig 6).
For a workload with 500 GB of daily data changes, this translates into:
- Mumbai → Delhi: ~$750/month
- Mumbai → Singapore: ~$1,200/month (+60 %)
- Mumbai → Sydney: ~$3,400/month (+360 %)
Consequently, network egress becomes one of the largest line items in DR TCO, especially for data-intensive workloads.
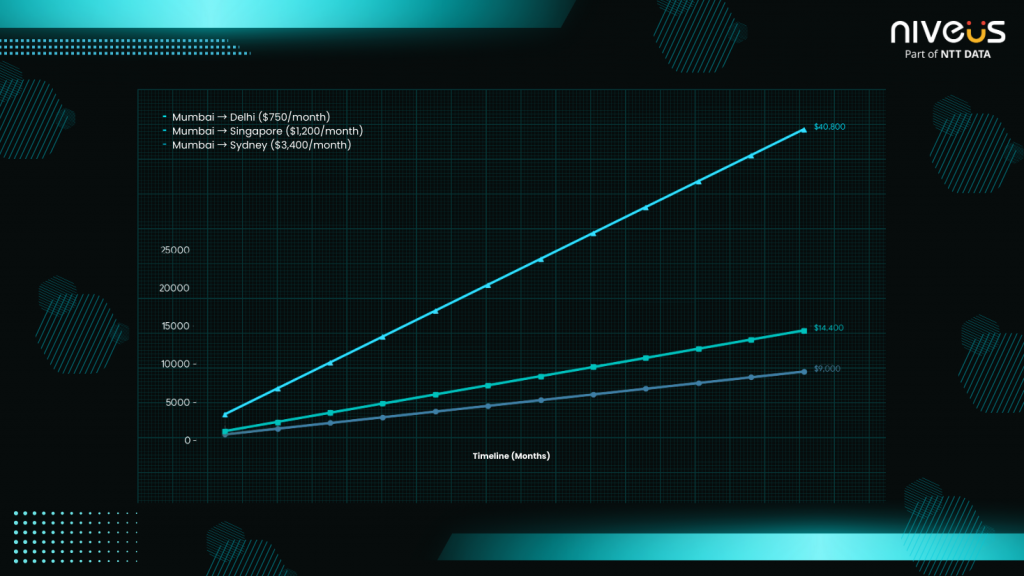
Fig 6: Visual illustration of cumulative DR replication costs across different geographic routes over a 12-month timeline.
Common DR Region Patterns in Practice
Applying this framework reveals consistent patterns among enterprises:
Pattern 1: In-Country Compliance (Mumbai → Delhi)
- Best for regulated sectors like BFSI
- Low latency and strong compliance alignment
- Cost-effective and operationally predictable
Pattern 2: Regional Diversification (Mumbai → Singapore)
- Works well for APAC SaaS and multinational workloads
- Broader risk separation
- Increased latency and cost with asynchronous replication
Pattern 3: Cross-Continental Separation (Mumbai → Sydney)
- Maximum geographic diversity and risk isolation
- Highest network costs (+360% vs. in-country)
- Asynchronous replication only (1-4 hr RPO)
- Suitable for global enterprises prioritizing geographic independence over latency
Alternative Pattern: Active-Active + Tertiary DR
- Continuous availability and near-zero downtime
- Complex and high cost (2.5–3x typical DR)
- Justified only for workloads where downtime (>$10K/min) is unacceptable
Conclusion
Disaster recovery region selection is a strategic decision that demands early attention, not a technical detail to resolve later. Distance, latency, compliance, and cost are interconnected constraints that shape what’s actually achievable when failure occurs. Organizations that apply this framework proactively build resilience into their architecture from day one, avoiding costly redesigns and ensuring recovery objectives align with business reality. The question isn’t whether disruption will happen; it’s whether your DR strategy can actually deliver when it does.
Read our whitepaperon Disaster Recovery on Google Cloud to explore how Hot and Warm DR strategies, real-time replication, and failover orchestration can keep your business resilient and minimize downtime.









