


Teams spend months building AI models that promise game-changing insights. Yet many projects still underdeliver or fail. The issue usually isn’t the model, algorithm, or computing power. Instead, incomplete and ungoverned data quietly undermines outcomes. In this blog, we’ll explore why the AI confidence gap exists, what truly AI-ready data looks like, and how tools like Google Dataplex help data teams turn messy, fragmented datasets into reliable fuel for high-performing models.
Build AI models on data you can trust.
Nearly 60% of organizations don’t measure the financial impact of poor data quality. However, that doesn’t reduce its impact. Bad data silently disrupts AI systems and damages customer experiences. Teams often blame downstream systems such as personalization engines or workflows. In reality, the problem starts much earlier at data collection. Activation doesn’t create instability; it exposes it. (Refer Fig 1).

Fig 1: Visual Illustration of the Hidden Cost of Poor Data Quality
The AI confidence gap
When AI projects underperform, the instinct is to blame the model, the algorithm, or the compute resources powering it. Roughly 80% of AI project time goes into cleaning, validating, and preparing data, not building models (Refer Fig 2). From a real-world perspective, a failed rollout might look like a recommendation engine showing irrelevant products, a credit scoring model misclassifying customers, or a marketing campaign triggering the wrong segments. Behind the scenes, teams struggle with inconsistent schemas, missing records, and undocumented transformations. Consequently, delays pile up. The real bottleneck isn’t AI; it’s the data feeding it.

Fig 2: Visual Illustration of the Data Preparation Reality Behind AI
What AI-Ready Data Actually Looks Like
AI-ready data goes beyond being “clean.” It must be structured, governed, and traceable. Research shows that poor data quality is the leading bottleneck in AI adoption, only 12% of organizations report their data is of sufficient quality for effective AI implementation, and 64% identify data quality as their top data integrity challenge, with many delaying AI initiatives because their data simply isn’t ready (Refer Fig 3).
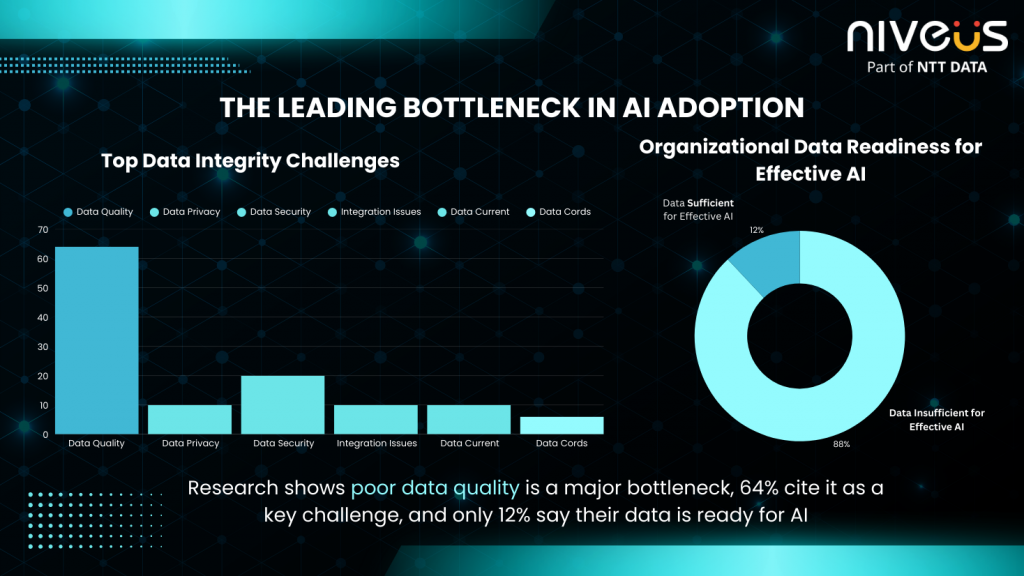
Fig 3: Visual Illustration of the Leading Bottleneck in AI Adoption
- Consistent schema across sources: Data fields are standardized and formatted uniformly, preventing mismatches and integration errors.
- Documented lineage from source to model: Every transformation is tracked, so teams know exactly how raw data becomes model input.
- Automated quality rules in place: Data is continuously validated against predefined rules to catch errors early.
- Profiled and scored for completeness: Records are measured for missing values, duplicates, and coverage gaps.
- Governed access and ownership defined: Teams know who is responsible for data and how it can be securely accessed and modified.
When these elements are in place, teams shift focus. Instead of fixing data, they build models that perform.
How Google Dataplex Fixes This
Data teams don’t just need access; they need confidence in their data. Google Dataplex addresses this by making AI-ready data easier to manage and act upon:
- Data Profiling automatically scans datasets across BigQuery, flagging anomalies, missing values, and inconsistencies that would otherwise go unnoticed. As a result, teams reduce manual effort.
- Auto Data Quality lets teams define rules once and enforce them continuously, reducing manual checks and preventing bad data from slipping into models.
- Data Lineage traces every transformation from source to model, giving analysts and engineers full visibility into how data flows and evolves, making debugging and audits faster and less error-prone.
- Universal Catalog creates a single, searchable repository of all data assets, so teams can quickly discover, understand, and trust the datasets they need for analysis or AI projects.
Together, these capabilities do more than clean data. They accelerate onboarding, improve model reliability, and reduce constant firefighting. With Dataplex, teams move from reactive fixes to proactive data management, letting AI perform as intended.
From Dirty Data to AI-Ready: A Quick Before/After
Consider a retail team struggling with an underperforming recommendation engine. Despite sophisticated algorithms, customers were receiving irrelevant suggestions, and engagement was dropping. The root cause? Duplicate customer records, inconsistent product codes, and untracked upstream schema changes quietly corrupted the model’s inputs.
This scenario is more common than many teams realize. Studies estimate that nearly 40% of analytics initiatives fail due to poor data quality, often because issues like duplicates, missing fields, or undocumented transformations go unnoticed until they affect downstream systems. (Refer Fig 4)

Fig 4: Visual Illustration of the Impact of Poor Data Quality on Analytics Initiatives
With Google Dataplex, the team can automatically profile datasets, detect anomalies, enforce data quality rules, and trace lineage across data pipelines. Instead of spending weeks manually investigating data issues, engineers gain immediate visibility into where problems originate and how they propagate across systems. The result is cleaner, governed, AI-ready data, allowing models to generate more accurate recommendations and deliver meaningful customer experiences.
Conclusion
Fixing AI starts with fixing data. Sophisticated models and cutting-edge algorithms can only perform as well as the data they rely on. By ensuring data is consistent, governed, and traceable, and by using tools like Google Dataplex to automate quality checks and surface hidden issues, organizations can close the AI confidence gap, reduce wasted effort, and unlock the true potential of their AI initiatives. Clean, trustworthy data isn’t just a technical requirement; it’s the foundation for AI that delivers real business impact.
Read our whitepaper on The Power of Pristine Data to explore how Dataplex accelerates data quality assurance, enforces automated quality rules, and helps enterprises derive real value from their data assets.
Appendix:
- https://gitnux.org/data-quality-statistics/
- https://optimusai.ai/data-scientists-spend-80-time-cleaning-data/
- https://www.gartner.com/en/newsroom/press-releases/2025-02-26-lack-of-ai-ready-data-puts-ai-projects-at-risk
- https://dataladder.com/wp-content/uploads/2019/07/Gartner-Study-40_of-the-anticipated-value-of-all-business-initiatives-is-never-achieved-due-to-poor-data-quality.pdf









