


Organizations across the globe are generating unprecedented volumes of data from customer interactions, business applications, digital platforms, connected IoT devices, and partner networks. As the number of data sources continues to grow, managing, integrating, and extracting value from this data has become increasingly complex. Data teams spend significant time manually building and maintaining pipelines handling ETL and ELT workflows, connecting and integrating systems, resolving schema mismatches, enforcing data quality, and troubleshooting failures.
On top of that, businesses face mounting pressure to deliver real-time insights, comply with evolving regulations, and meet data sovereignty requirements. These compounding challenges slow decision-making and drive up operational costs.
Modern data engineering starts with intelligent automation.
Data teams dedicate 53% of engineering time to maintaining existing pipelines rather than building new data products and analytics capabilities. As data volumes continue to surge, businesses need smarter, faster ways to build, operate, and optimize their data environments.
That’s where Data Engineering Agents come in. Powered by generative AI, these agents automate the process of building and optimizing data pipelines, significantly reducing manual effort and accelerating delivery. Google Cloud is at the forefront with solutions like Gemini, Vertex AI, and the BigQuery Data Engineering Agent. In this blog, we explore what Data Engineering Agents do, how they accelerate data engineering, and the tangible business benefits they deliver.
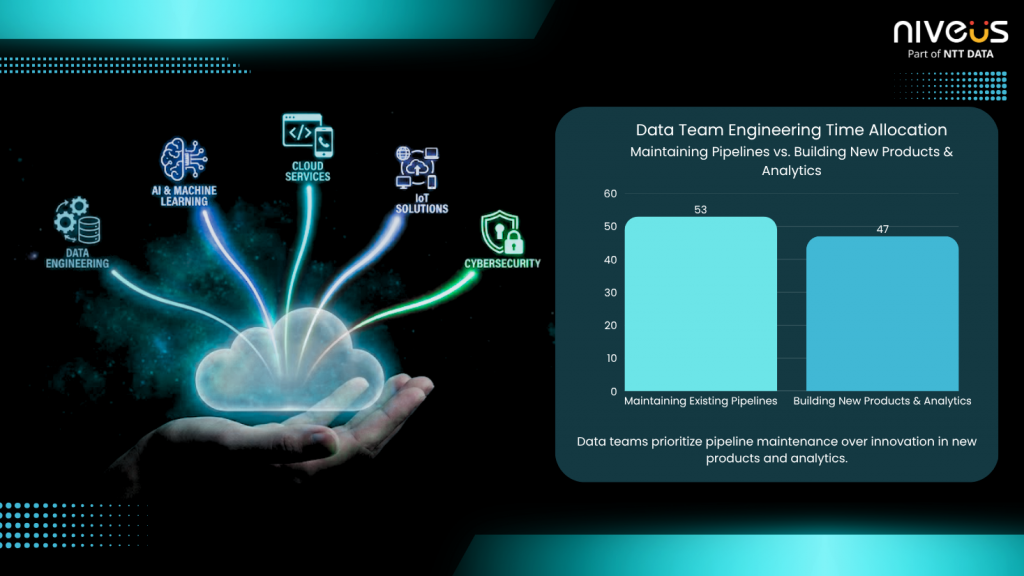
Fig 1: Visual Illustration of Data Engineering Time Allocation
What Are Data Engineering Agents?
Data Engineering Agents are AI-powered systems that help data teams design, build, optimize, and manage data workflows using natural language and contextual understanding. Unlike traditional automation tools that execute predefined instructions, these agents understand intent, reason through complex tasks, and generate the steps required to achieve a desired outcome.
What sets these modern agents apart is their use of powerful language models and deep knowledge of data systems. They handle everything from ingesting and transforming data to enforcing quality checks, resolving issues, and keeping pipelines running smoothly with minimal human intervention.
As data environments grow more complex, organizations are moving beyond simple rule-based automation. Research found that data professionals spend approximately 45% of their time on data preparation tasks, including cleaning, organizing, and managing data. Data Engineering Agents help reduce this burden by automating repetitive activities and enabling engineers to focus on delivering business value through analytics, governance, and platform innovation.

Fig 2: Visual Illustration of Data Professional Time Allocation
From Automation to Autonomous Data Engineering
The evolution of data engineering spans three distinct stages:
| Capability | Traditional Automation | AI Copilot | Data Engineering Agent |
| User Interaction | Scripts and rules | Natural language assistance | Goal-based requests |
| Context Awareness | Limited to the script definitions | Moderate | High |
| Pipeline Creation | Manual | Assisted | Automated |
| Optimization Recommendations | No | Yes | Yes |
| Troubleshooting | Manual | Guided | Agent-assisted |
| Workflow Execution | Rule-based | Human-directed | Autonomous within guardrails |
Traditional automation relies on predefined workflows and requires engineers to build and maintain pipelines manually.
AI copilots boost productivity by helping engineers generate SQL, write code, explain queries, and surface optimization recommendations, but engineers remain responsible for planning and execution.
Data Engineering Agents go further. They understand objectives, generate workflows, recommend best practices, and help resolve issues across the full data lifecycle. By combining reasoning, context awareness, and automation, they reduce manual effort and accelerate data delivery.
How Google Cloud Is Advancing Agentic Data Engineering
Google Cloud is making it easier for organizations to adopt smarter, AI-driven data engineering by embedding intelligent capabilities directly into BigQuery, Gemini, Vertex AI, and Dataplex.
The BigQuery Data Engineering Agent is a strong example. Engineers describe what they need in natural language, and the agent translates those inputs into production-ready data pipelines. It sets up ingestion and transformation workflows, recommends performance improvements, generates documentation, enforces data quality checks, and assists with troubleshooting all within a governed environment.
Google’s approach goes beyond simple code generation. By drawing on metadata from Dataplex and context from the broader Google Cloud data platform, the Data Engineering Agent develops a deeper understanding of datasets, business rules, and governance requirements, producing outputs that are more relevant, accurate, and maintainable.
This marks a meaningful shift: from manually constructing data pipelines to defining business objectives and letting AI-powered agents handle much of the underlying implementation.
Core Capabilities of Data Engineering Agents
- Reasoning: Understands business requirements and translates them into effective technical workflows.
- Workflow Orchestration: Coordinates data ingestion, transformation, validation, monitoring, and delivery across systems.
- Context Awareness: Uses metadata, lineage, schemas, and governance policies to generate relevant, compliant outputs.
- Autonomous Execution: Automates pipeline creation, optimization, documentation, quality enforcement, and troubleshooting within defined guardrails.

Fig 3: Visual Illustration of Enhancing Data Pipelines with AI Agents
Key Challenges in Traditional Data Engineering
As organizations scale their data ecosystems, engineering teams face growing pressure to deliver reliable, high-quality data faster. Traditional data engineering processes, however, remain heavily dependent on manual effort, making them difficult to scale and increasingly costly to maintain.
- Manual ETL and ELT Development: Building pipelines requires engineers to connect multiple systems, develop transformation logic, manage schema changes, and maintain workflows. As data sources multiply, pipeline development grows exponentially more complex and time-consuming.
- Data Quality Issues: Inconsistent formats, duplicate records, missing values, and data drift undermine the accuracy of analytics and AI initiatives. Detecting and resolving these issues demands significant manual investigation.
- Pipeline Failures and Debugging: Modern pipelines span multiple interconnected systems and dependencies. When failures occur, identifying the root cause and restoring operations is a lengthy process with real consequences for downstream analytics.
- Metadata and Governance Complexity: Managing metadata, data lineage, access controls, and compliance requirements becomes increasingly challenging as environments expand. Weak governance reduces visibility, introduces compliance risk, and erodes trust in data assets.
- Slow Delivery of Analytics: Business teams expect faster access to insights, but traditional development cycles involving manual coding, testing, and troubleshooting consistently delay analytics projects and slow decision-making.

Fig 4: Visual Illustration of Traditional Data Engineering Challenges
Business Impact
These challenges create a ripple effect across the organization:
- Increased operational overhead
- Delayed delivery of business insights
- Reduced data reliability and trust
- Higher engineering effort and costs
- Slower innovation and decision-making
As data complexity continues to rise, organizations need more intelligent approaches to managing and scaling their data engineering operations.
How AI Agents Accelerate Data Engineering Activities
Google Cloud embeds AI directly into the data engineering lifecycle through BigQuery, Gemini, Vertex AI, and Dataplex. This enables engineers to shift from manual pipeline development to intent-driven engineering, where AI assists with or automates key stages of data workflows.
- Intelligent Pipeline Generation and Data Preparation: AI agents generate pipelines, transformations, and data-preparation workflows directly from natural-language inputs.
- Agentic Pipelines with BigQuery Data Engineering Agent: The BigQuery Data Engineering Agent automates end-to-end pipeline creation, reducing manual coding and accelerating delivery timelines.
- Native Gemini Assistance in SQL Workflows: Gemini helps engineers generate, optimize, and understand SQL queries directly in BigQuery.
- SQL Translation and Modernization Acceleration: Gemini-powered agents simplify legacy SQL migration and modernization for BigQuery environments, reducing complexity and risk.
- AI-Driven Troubleshooting and Data Quality Monitoring: AI agents reactively detect anomalies, automate data quality checks, and accelerate issue resolution before problems cascade downstream.
- Conversational Analytics – Talk to Your Data: Gemini and Vertex AI enable users to query data in natural language, enabling faster, self-service insight generation.
Fig 5: Visual Illustration of Synergy of AI and Data Engineering on Google Cloud
Business Benefits of AI-Driven Data Engineering
AI-powered data engineering improves speed, efficiency, and reliability across the data lifecycle by reducing manual effort and enhancing developer productivity. These capabilities operate within governed environments where engineers retain full control over design and deployment decisions.
| Challenge | AI Capability | Business Impact |
| Slow pipeline development | AI-assisted pipeline generation using natural language and templates | Faster pipeline design and reduced time-to-insight |
| High engineering effort in ETL/ELT development | BigQuery Data Engineering Agent supporting workflow creation and transformation logic generation | Reduced manual coding and improved engineering productivity |
| Complex SQL development and debugging | Gemini-assisted SQL generation, explanation, and optimization | Faster query development and improved query efficiency |
| Legacy SQL and multi-platform dependencies | AI-assisted SQL translation and modernization for BigQuery | Accelerated migration and reduced modernization complexity |
| Pipeline failures and troubleshooting effort | AI-assisted root-cause analysis and guided troubleshooting using metadata and logs | Faster issue resolution and reduced operational downtime |
| Data quality inconsistencies | Configured data quality rules supported by AI-driven anomaly detection and monitoring insights | Improved data reliability and stronger data governance |
Overall Impact
AI-driven data engineering enables teams to reduce repetitive work while improving consistency across data workflows. Engineers can redirect their focus toward architecture design, governance, and optimization, rather than routine pipeline maintenance.
The result is faster delivery of analytics use cases, improved operational efficiency, and more scalable data platforms built on Google Cloud.
The Future of Autonomous Data Engineering
- Self-healing pipelines: AI-powered pipelines automatically detect and resolve common issues, reducing downtime and improving reliability without manual intervention.
- Multi-agent orchestration: Multiple specialized AI agents collaborate across data workflows to improve efficiency and operational scalability.
- AI-native data platforms: These platforms embed intelligence directly into data management processes, simplifying both development and day-to-day operations.
- Enterprise guardrails for autonomous data systems: Governance controls, policies, and approval workflows ensure that autonomous systems operate securely and in compliance with regulatory requirements.
- The evolving role of data engineers: Data engineers will increasingly focus on architecture, governance, and strategy rather than routine operational tasks.
This transition does not diminish the importance of engineers. It elevates their role toward higher-value decision-making and system design in AI-driven data ecosystems.

Fig 6: Visual Illustration of Unveiling the Dimensions of Autonomous Data Engineering
Conclusion
Data engineering is under strain. Manual pipelines and growing data complexity across APAC are pushing traditional approaches beyond their limits. Teams are expected to deliver faster insights while simultaneously managing greater scale, governance demands, and reliability pressures.
Data Engineering Agents fundamentally change this equation. With Google Cloud capabilities spanning BigQuery, Gemini, Vertex AI, and Dataplex, Google Cloud reduces repetitive work, accelerates delivery, and raises the bar for data quality. The outcome is straightforward: faster pipelines, more reliable data, and quicker decisions. Data engineers move from maintenance-heavy operations to designing and governing smarter, more resilient data systems.
This is not simply an efficiency gain. It is a strategic shift toward intelligent, AI-driven data platforms built for enterprise scale.









