


Research from the IBM Institute for Business Value (IBM IBV) indicates that organizations equipped with the most advanced security capabilities experienced a 43% higher revenue growth compared to their peers over a span of five years. The abundance of data that marks the era, also brings forth significant challenges, particularly when it comes to ensuring its security and integrity. With the ever-evolving threat landscape and stringent regulatory requirements, organizations must adopt robust measures to protect their data assets. Among the myriad of solutions available, Google Cloud stands out as a trusted platform offering a suite of powerful tools and features designed to bolster data security. In this blog, we delve into the realm of Google Cloud data security, focusing specifically on data masking techniques using policy tags.
Secure Sensitive Information with Google Cloud
Additionally, we’ll examine the role of policy tags in masking data and thereby enhancing data governance and compliance efforts. As we explore Google Cloud data security, we’ll uncover the best practices, practical insights, and examples to illustrate the significance of data masking techniques with policy tags in safeguarding your data.
Data Security in GCP: fortifying your data defenses.
Data security is paramount in today’s digital landscape, with organizations striving to protect their valuable information assets from a gauntlet of threats, including theft, unauthorized access, and corruption. Within Google Cloud Platform (GCP), data security is achieved through a robust framework of encryption mechanisms, providing comprehensive protection throughout the data lifecycle.
Encryption serves as the cornerstone of data security in GCP, offering multiple layers of defense against potential breaches. GCP provides built-in encryption options, including encryption at rest, encryption in transit, and even encryption in use, ensuring that data remains protected regardless of its state or location within the cloud infrastructure. This ensures that even if unauthorized access occurs, the encrypted data remains indecipherable without the corresponding decryption keys, thus mitigating the risk of data exposure.
In addition to these foundational encryption mechanisms, organizations can further enhance data security in GCP by leveraging data masking techniques. Data masking involves replacing sensitive data elements, such as personally identifiable information (PII), with fictitious but realistic values, thereby obscuring the original data while maintaining its usability for authorized users.
Data masking is particularly valuable when dealing with sensitive data sets that require processing or analysis within GCP environments. By applying masking techniques to customer PII data, organizations can adhere to regulatory requirements, such as GDPR or HIPAA, while minimizing the risk of unauthorized access or data leakage. [1] Let’s take a deeper look at data masking.
Data Masking Techniques
Data masking, a method of obfuscating sensitive information within datasets, serves as a frontline defense against unauthorized access and data breaches. By disguising or replacing sensitive data with realistic but fictional values, organizations can limit exposure without compromising usability. Let’s explore various data masking techniques available within Google Cloud, highlighting their effectiveness in safeguarding sensitive information across diverse use cases.
Some common data masking techniques include:
- Substitution: This technique involves replacing sensitive data with fictitious but realistic values. For example, replacing actual names with randomly generated names or using pseudonyms.
- Shuffling: Shuffling involves randomly reordering the values of sensitive data within a dataset. This helps to preserve the overall distribution of the data while preventing individual records from being linked to specific individuals.
- Encryption: Encryption involves transforming sensitive data into an unreadable format using cryptographic algorithms. Access to the original data is restricted to authorized users possessing the necessary decryption keys.
- Tokenization: Tokenization replaces sensitive data with unique tokens or references that have no meaning on their own. The original data is stored securely in a separate location, and only authorized users can access it using the corresponding token.
- Masking: Masking involves partially or fully obscuring sensitive data by replacing certain characters with placeholders, such as masking credit card numbers or social security numbers.
- Format-preserving encryption: This technique encrypts sensitive data while preserving its original format, such as encrypting a credit card number while ensuring it remains a valid credit card number.
- Dynamic masking: Dynamic masking applies masking rules based on predefined policies or access controls, allowing sensitive data to be selectively masked or unmasked depending on the user’s permissions.
The purpose is to safeguard the original data while offering a functional alternative when the actual data isn’t required. A key principle of data masking is maintaining the data format while altering only the values. Data masking helps mitigate the impact of a data breach. For instance, consider a database containing sensitive financial data alongside less critical customer information. Sales personnel may need access to customer data but not financial data. By applying data masking, sensitive financial data can be obscured. In the event of a compromised salesperson’s account, attackers would be unable to access the financial data. Similarly, data masking protects against insider threats, as unauthorized internal parties attempting to access data will encounter masked information, minimizing potential harm.
Numerous data security regulations mandate the implementation of data masking, particularly for Personally Identifiable Information (PII). BigQuery offers data masking capabilities at the column level, enabling users to selectively conceal column data for specific user groups while still permitting access to the column. [2]
GCP Tags & The Role They Play in Data Masking
Policy tags play a crucial role in data masking within Google Cloud Platform (GCP), offering a flexible and granular approach to controlling access to sensitive data. These tags provide a mechanism for classifying data based on its sensitivity, allowing organizations to enforce access controls and apply data protection measures accordingly. Here’s how it helps:
- Tags for Resource Annotation and Policy Enforcement: Tags provide a way to create annotations for resources, and in some cases conditionally allow or deny policies based on whether a resource has a specific tag. Utilizing tags and implementing policies with conditional enforcement allows for precise control throughout your resource hierarchy.
- IAM for Granular Access Control: IAM lets you grant granular access to specific BigQuery resources and helps prevent access to other resources. For any user, group, or service account accessing a Google Cloud API, it’s essential that they possess the necessary IAM permissions to utilize the resource.
- Policy Tags for Secure Data Handling in BigQuery: Policy Tags are used in the BigQuery platform of GCP to secure the PII data and give column level access control. BigQuery provides fine-grained access control and dynamic data masking for sensitive table columns through policy tags, supporting type-based classification of data. [[3,5]
Use cases for Policy Tags
Policy tags through data masking safeguards sensitive Personally Identifiable Information (PII) within datasets, ensuring protection against unauthorized access and misuse of information. Policy tags are extensively used to protect PII such as email addresses, government identification numbers, customer names, ages, card numbers, and phone numbers. By applying policy tags to these data elements, organizations can enforce strict access controls and data masking rules, preventing unauthorized users from accessing or viewing sensitive information. Let’s explore some common use cases where policy tags are applied to secure sensitive data:
- Financial Data Security: Financial datasets often contain sensitive information such as bank account numbers, credit card details, and transaction histories. Policy tags enable organizations to classify and protect financial data effectively, ensuring compliance with regulatory requirements such as PCI DSS (Payment Card Industry Data Security Standard) and safeguarding against potential breaches or fraud.
- Customer Order Data Protection: Customer order data, including purchase history, shipping addresses, and payment information, is highly sensitive and requires robust security measures. By applying policy tags to customer order datasets, organizations can enforce access controls based on user roles and responsibilities, limiting exposure to sensitive information and mitigating the risk of data breaches or unauthorized access.
- Healthcare Data Privacy: In the healthcare sector, patient information such as medical records, diagnoses, and treatment histories are subject to strict privacy regulations, including HIPAA (Health Insurance Portability and Accountability Act). Policy tags play a crucial role in ensuring compliance with these regulations by enforcing access controls, data encryption, and dynamic data masking for sensitive healthcare data.
- Employee Data Confidentiality: Employee records, including salary details, social security numbers, and performance evaluations, require protection to prevent unauthorized access or misuse. Policy tags allow organizations to apply data masking techniques and access controls to employee datasets, safeguarding sensitive information and maintaining confidentiality.
In summary, policy tags are instrumental in addressing a wide range of use cases where data privacy and security are paramount. By implementing policy tags effectively, organizations can mitigate risks, achieve regulatory compliance, and uphold the confidentiality and integrity of their data assets. [6]
Implementation: Applying Google Cloud Policy Tags in BigQuery
In this section, let’s delve into the practical implementation of applying policy tags in BigQuery to enforce access controls and secure sensitive data.
To begin, within the BigQuery UI, navigate to the Policy Tags option to establish column-level access control. Refer Fig 1. [4]
Fig 1: Policy Tags UI
Setup Taxonomy and Policy Tags: Create a Taxonomy with one or more Policy Tags, specifying the region for the Taxonomy. A data policy links a data masking rule with one or more principals, representing users or groups, to the corresponding policy tag. These tags, such as email, Govt_ID, or Phone_Number, represent Personally Identifiable Information (PII). To apply policy tags from a taxonomy to a table column, the taxonomy and the table must exist in the same regional location. Refer Fig 2 for creating Taxonomy. [4]
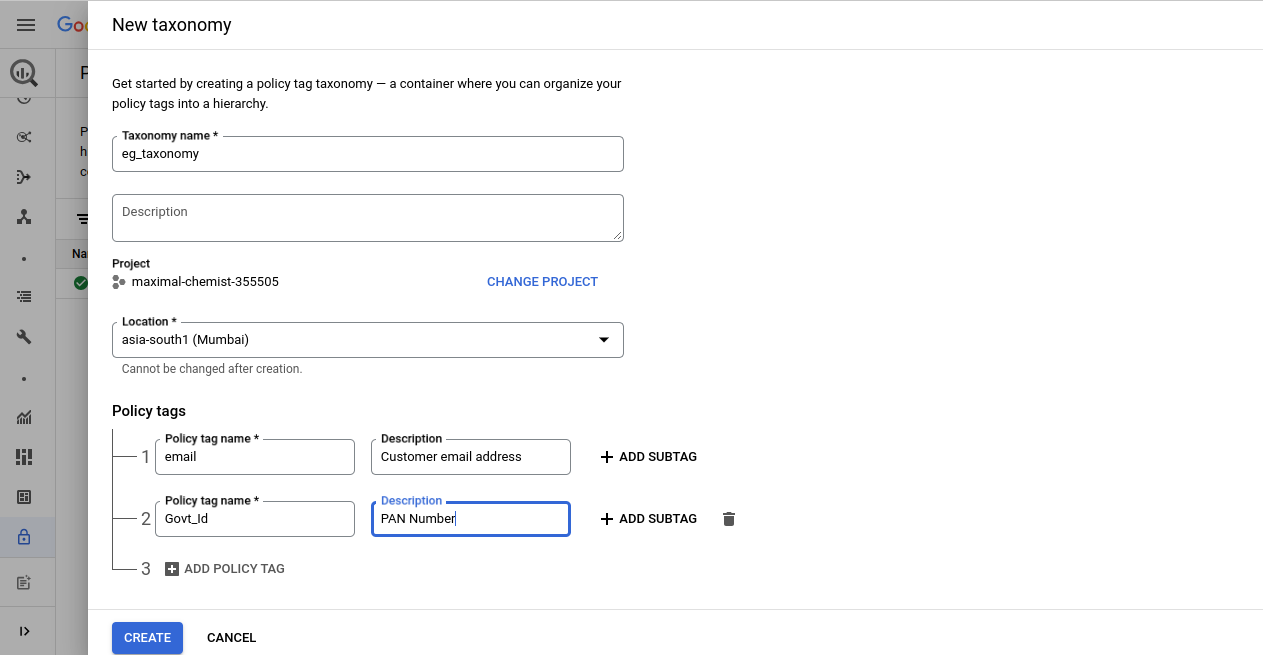
Fig 2: Creating Taxonomy
Creating Data Policies: When creating a data policy via the Google Cloud console, both the data masking rule and principals are specified in a single step. Conversely, using the BigQuery Data Policy API combines the creation of the data policy and masking rule in one step, followed by specifying the principals in a second step. After setting up a taxonomy, enabling the BigQuery DataPolicy API allows for the management of Data Policies. Data masking rules are then defined based on specific requirements. Refer Fig 3. [4]
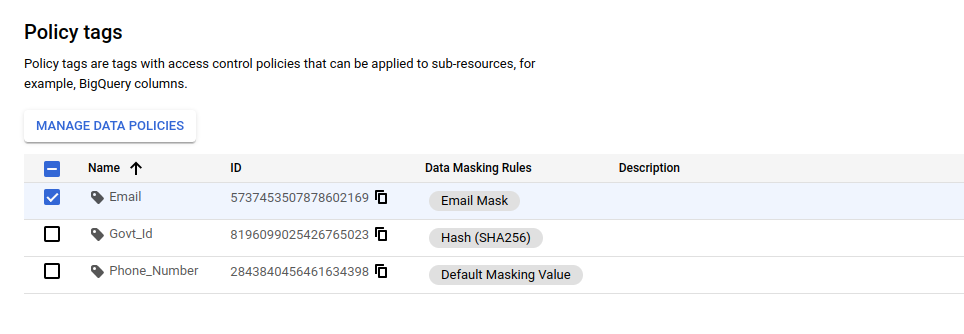
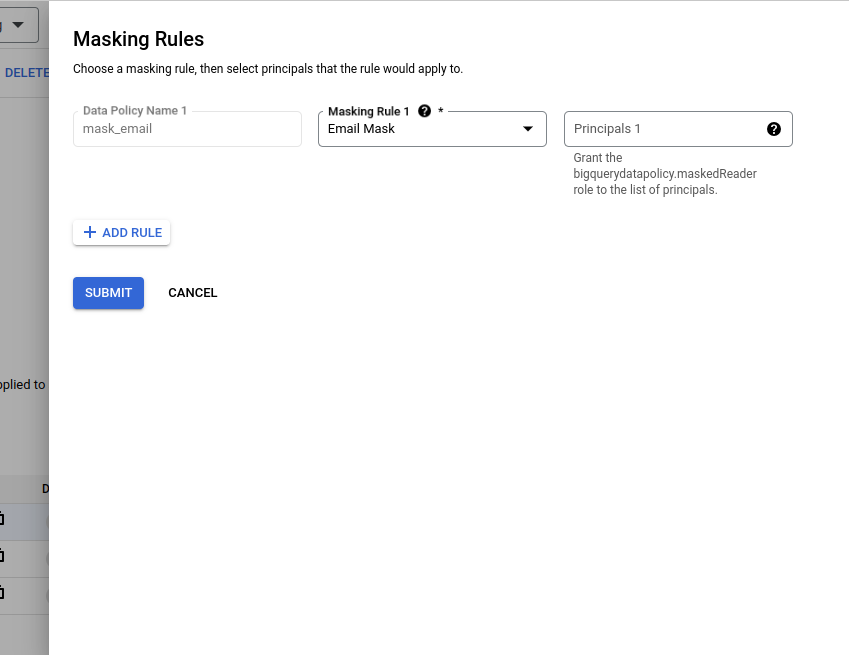
Fig 3: Specify Masking Rules
Implementing Access Control and Policy Tag Association in BigQuery: Ensure access control is enforced on the taxonomy housing the policy tags. Then, associate the policy tags with columns in BigQuery tables to implement data policies. Access the Edit Schema option in a BigQuery table, select the relevant columns, add the desired policy tags, and save the configuration. Refer Fig 4,5. [4]
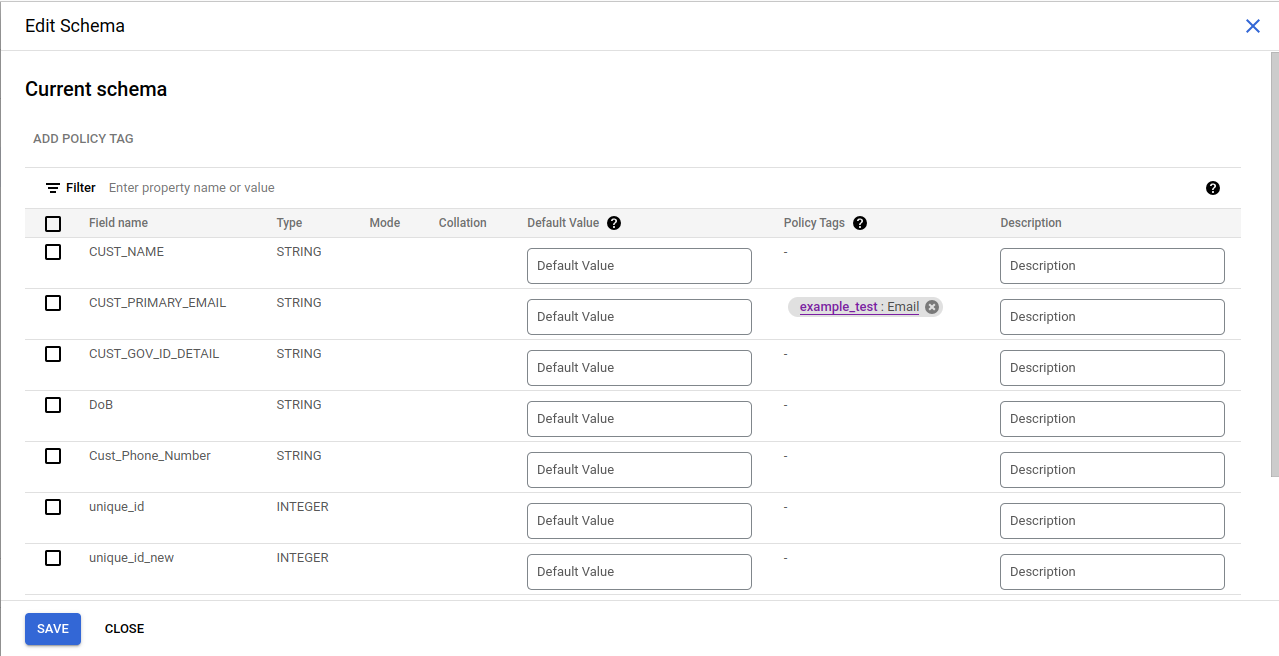
Fig 4: Adding Policy Tags to columns in a table
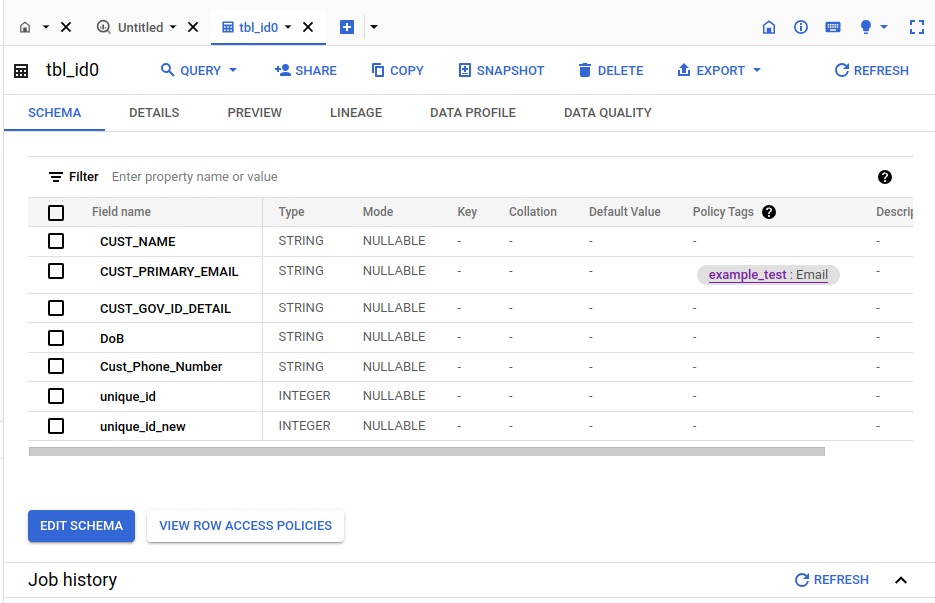
Fig 5: Table with a policy tag applied
Due to the Data Policy restriction, any user will be unable to view the tagged Personally Identifiable Information (PII) column. Refer Fig 6. [4]
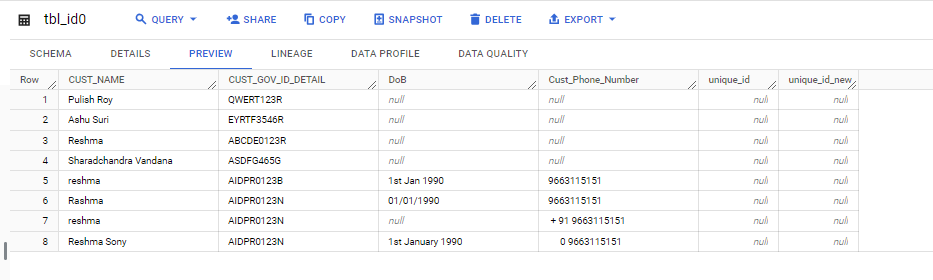
Fig 6: Table with the column hidden with data policy tag
Assigning BigQuery Masked Reader Role for Access to Masked Data: Designate users requiring access to masked data to the BigQuery Masked Reader role. This role grants specific users access to the masked Personally Identifiable Information (PII) data. Refer Fig 7. [4]
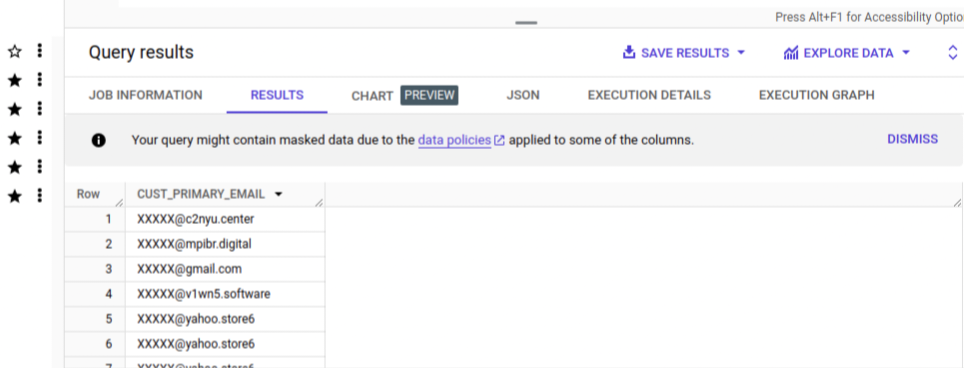
Fig 7: Masked Data user
Facilitating Column-Level Access Control with Data Catalog Fine-Grained Reader Role: By granting one or more principles the Data Catalog Fine-Grained Reader role, the policy tag associated with a data policy can also facilitate column-level access control. This authorization enables these principles to access the original, unmasked column data. Refer Fig 8. [4]
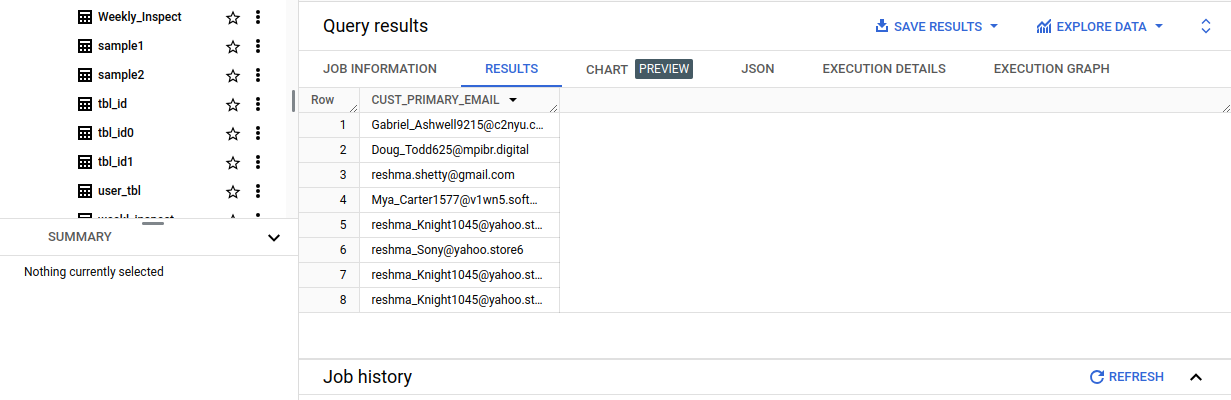
Fig 8: Fine-Grained User
Masking options for different PII:
PIIs, such as customer emails mentioned above, utilize the email mask option within the masking rules defined in the policy tags. Other PII types, like phone numbers, may opt for Default Masking values, while government IDs such as PAN numbers can employ Hashed values as masking rules for data masking. Refer Fig 9. [4]
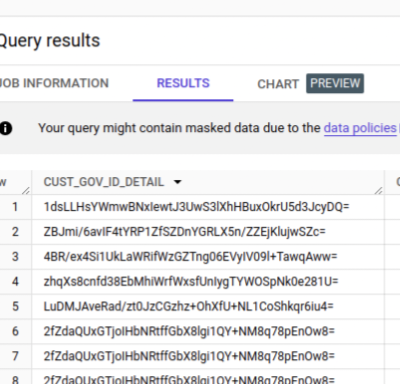
Fig 9: Govt_Id has been masked using Hash(SHA256)
Best Practices for Access Control and Classifying Data
To establish effective data security measures within your organization, consider implementing the following best practices:
- Define a Hierarchical Data Classification: Construct a hierarchy of data classes tailored to your business needs. Identify primary data types such as Personally Identifiable Information (PII), Financial data, or Customer Order data. Utilize policy tags to apply a single data class to multiple data columns efficiently.
- Assess User Group Requirements: Evaluate the data access needs of different user groups within the organization. Some groups may require access to business-sensitive data, while others may primarily need access to PII. Tailor access permissions accordingly to ensure appropriate data handling practices.
- Implement Sensitivity-Based Classification: During taxonomy creation, classify data sensitivity using categories such as High, Medium, and Low policy tags. This classification helps in granular access control and ensures that sensitive data receives appropriate protection.
- Assign Access Roles Based on Sensitivity: Assign the Data Catalog Fine-Grained Reader role to users or groups requiring access to Low sensitivity data. This role provides controlled access to data while maintaining security standards.
- Flexibility in Access Control: Maintain flexibility in access control by allowing the movement of policy tags between tiers. This enables further restriction of access without the need for extensive reclassification efforts, ensuring agility in data security management.
By implementing these best practices, organizations can establish a robust framework for data classification and access control, promoting data security and compliance across various business operations. [6]
Conclusion – Safeguarding Sensitive Data with Policy Tags in GCP
In conclusion, safeguarding sensitive data is imperative in today’s digital landscape, where organizations face an array of threats and regulatory obligations. With the proliferation of data and evolving threat vectors, robust measures are essential to protect valuable information assets and maintain trust with customers and stakeholders.
Google Cloud Platform (GCP) offers a comprehensive suite of tools and features, including advanced encryption mechanisms and data masking techniques using policy tags, to fortify data security efforts. By leveraging these capabilities, organizations can mitigate risks, achieve regulatory compliance, and uphold the confidentiality and integrity of their data assets.
Through the implementation of policy tags in BigQuery, organizations can enforce granular access controls and dynamically mask sensitive data, ensuring that only authorized users have access to the information they need while maintaining privacy and compliance standards. From financial data security to healthcare data privacy and beyond, policy tags play a crucial role in addressing diverse use cases and protecting against unauthorized access and misuse of information.
By adhering to best practices such as defining hierarchical data classification, assessing user group requirements, and implementing sensitivity-based classification, organizations can establish a robust framework for data security and access control. This framework promotes agility, flexibility, and adherence to security standards, enabling organizations to effectively navigate the complex landscape of data security and emerge as trusted stewards of sensitive information.
In essence, by embracing Google Cloud’s data security capabilities and adopting a proactive approach to data protection, organizations can not only mitigate risks but also unlock opportunities for innovation and growth in an increasingly data-driven world.









