


With global data volumes expected to exceed 180 zettabytes by 2025, businesses need advanced analytics that can mine their vast datasets faster. As a powerful, serverless, and scalable data warehouse, BigQuery enables advanced analytics on large datasets, making it a key tool for large enterprises. Studies indicate that modern cloud data warehouses can reduce time-to-insight by up to 70%, while Forrester notes a 2.3x improvement in decision-making speed. However, to fully realize these benefits, best practices must be followed when designing a BigQuery data warehouse. In this blog, we’ll explore BigQuery data warehouse best practices for designing a secure, scalable, and cost-efficient data warehouse using Google BigQuery covering everything from schema design to machine learning integration.
Start building a smarter data warehouse with BigQuery
The modern data landscape demands solutions that can handle exponentially growing data volumes while maintaining query performance and controlling costs. Recent industry research shows that 65% of enterprises identify performance and cost as the top challenges when scaling their analytics workloads. Google BigQuery, built on Dremel technology, offers powerful advantages such as automatic scaling, columnar storage, and distributed query execution. However, realizing these benefits requires thoughtful design decisions and adherence to proven best practices.
Best Practices for Data Warehouse Design in BigQuery
This comprehensive guide covers critical aspects of BigQuery data warehouse design, from fundamental schema considerations to advanced optimization techniques. Whether you’re migrating from traditional data warehouses or building a new analytics platform, these practices will help you create a robust, scalable, and cost-effective data warehouse solution. In fact, studies show that optimized data schema design can improve query performance by up to 70% and reduce storage costs by 30–40%, especially when leveraging BigQuery’s columnar storage and partitioning capabilities. To fully realize these benefits, it’s critical to follow BigQuery data warehouse best practices from schema design and performance tuning to machine learning integration and cost control.
1. Schema Design and Optimization
Schema design in BigQuery is crucial for performance and cost efficiency. The right schema choices can dramatically impact query performance, storage costs, and overall system maintainability.
- Why denormalize: In a denormalized database, data retrieval operations often become simpler and quicker because fewer joins are required, reducing the overall query execution time. This approach is particularly useful in data warehousing and analytical databases, like BigQuery, where read operations are more frequent than write operations.

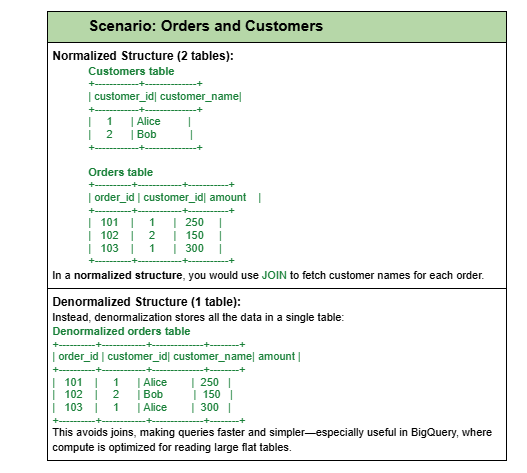
- Why partition or cluster: Partitioning and clustering are powerful features in BigQuery that help optimize storage and query performance. By splitting a large table into smaller partitions, you can improve query performance and control costs by reducing the number of bytes read by a query. A clustered table implies organizing the data contained within the table according to single or multiple columns to optimize the queries when applying specific constraints.
Partitioning & Clustering Best Practices:
- Time-based Partitioning: Use date or timestamp columns for partitioning when dealing with time-series data. This enables efficient time-range queries and automatic partition pruning
- Integer Range Partitioning: For non-temporal data, use integer range partitioning based on frequently queried numeric columns
- Partition Pruning: Design queries to take advantage of partition pruning by including partition column filters in WHERE clauses
- Column Selection: Choose clustering columns based on query patterns – typically columns used in WHERE clauses, JOIN conditions, and GROUP BY statements
- Column Order: Order clustering columns by cardinality (lowest to highest) and query frequency
- Why limit no of columns in query: Use SELECT statements wisely—retrieve only the columns you need to minimize the amount of data processed. This practice, known as columnar optimization, is particularly important in BigQuery’s columnar storage system where you pay for data scanned, not data stored.
Column Selection Strategies:
- Avoid SELECT: Always specify required columns explicitly to minimize data processing costs
- Column Pruning: Design tables with query patterns in mind, potentially creating separate tables for different analytical use cases
- Data Type Optimization: Choose appropriate data types to minimize storage and processing overhead
- Nested and Repeated Fields: Leverage BigQuery’s support for complex data types to reduce table joins and improve query performance
Reference for more details: https://cloud.google.com/bigquery/docs/best-practices-performance-overview
2. Data Ingestion and Storage
Effective data ingestion and storage strategies are vital for a well-performing BigQuery DW. The choice of ingestion method and storage format significantly impacts both performance and cost efficiency.
- Batch vs. Streaming:
- Batch Loading: Use batch loading for large-scale data ingestion to optimize costs. Batch loading is ideal for historical data migration, daily ETL processes, and scenarios where near-real-time data is acceptable. Benefits include lower costs, higher throughput, and better resource utilization
- Streaming API: Use Streaming API for real-time data updates when necessary. Streaming ingestion enables real-time analytics, immediate data availability, and supports use cases requiring low-latency data processing
- Compressed and Optimized File Formats:
- Parquet Format: Prefer Parquet format for optimal compression ratios and query performance. Parquet’s columnar storage aligns perfectly with BigQuery’s architecture
- Avro Format: Use Avro for schema evolution scenarios and when dealing with complex nested data structures
- ORC Format: Consider ORC for specific use cases requiring high compression ratios
- JSON Considerations: While BigQuery supports JSON, consider converting to structured formats for better performance
- Optimize Data Retention:
- Time-to-Live (TTL) Policies: Use TTL policies to automatically delete outdated data, reducing storage costs and improving query performance by limiting data scan ranges
- Historical Partition Expiration: Implement automated partition expiration to manage storage costs while maintaining necessary historical data
- Tiered Storage Strategy: Design multi-tier storage approaches with hot, warm, and cold data classifications
3. Query Optimization
Optimizing queries in BigQuery is essential for controlling costs and improving performance. Query optimization involves both writing efficient SQL and leveraging BigQuery’s advanced features.
- SELECT Only Required Columns: Reduce query costs and improve performance by avoiding SELECT *.
- Use Filters Early: Apply WHERE clauses to minimize scanned data.
- Leverage Materialized Views and BI Engine:
- Use materialized views for frequently accessed aggregated data.
- Use BI Engine to accelerate dashboard performance.
- Take Advantage of Query Caching: BigQuery caches query results for 24 hours; reuse cached results when possible.
- Use Approximate Aggregation Functions: For large datasets, functions like APPROX_COUNT_DISTINCT can be faster and more cost-effective than their exact counterparts.
- Optimize JOIN Patterns: Be mindful of how you structure JOIN operations, especially in queries involving large datasets, to ensure efficient execution.
4. Cost Management and Optimization
Effective cost management is a key aspect of BigQuery DW design. It involves proactively monitoring usage, setting budgets using BigQuery Cost Controls, and enabling Google Cloud Billing Reports to track spending.
- Monitor and Set Budgets:
- BigQuery Cost Controls: Use BigQuery Cost Controls to manage query and storage costs through custom quotas, project-level controls, and user-based restrictions
- Google Cloud Billing Reports: Enable Google Cloud Billing Reports to track usage patterns, identify cost drivers, and optimize spending across projects and teams
- Build Dashboards: Create comprehensive dashboards to view usage patterns, cost trends, and comparative analysis across different time periods and user groups
 Eg: Looker studio dashboard showing graphical summary of BQ usage |
- Optimize Storage Costs:
- Use Long-Term Storage Pricing for infrequently accessed data.
- Archive or delete unused datasets to reduce costs.
- Use data labels to categorize tables and track costs by business function, environment, or data classification.
- Regularly review the cost breakdown in BigQuery’s console to identify optimization opportunities.
- Optimize Query Costs:
- Use dry-run queries to estimate cost before execution, preventing expensive query mistakes
- Use BI Engine Reservations for frequent dashboard queries to achieve predictable costs and improved performance.
- Consider slot reservations for predictable workloads to achieve cost savings and performance guarantees
5. Security and Governance
Security and governance are paramount in BigQuery DW design to protect sensitive data and ensure compliance with regulatory requirements.
- Identity and Access Management (IAM):
- Implement fine-grained access controls at dataset and table levels.
- Use service accounts for automated workflows.
- Data Masking and Row-Level Security:
- Implement column-level security for sensitive data.
- Use row-level security policies to control data access based on user roles.



- Data Encryption:
- All data at rest in GCP is automatically encrypted using Google-managed keys.
- Use Customer-Managed Encryption Keys (CMEK) for additional security. CMEK lets you control the encryption keys that protect your data, instead of relying solely on Google-managed default encryption.
Reference: https://cloud.google.com/bigquery/docs/customer-managed-encryption
- Audit and Compliance:
- Enable Cloud Audit Logs for monitoring and compliance.
- Use BigQuery Data Catalog for metadata management and governance.
6. BigQuery Automatic Optimization Features
- BigQuery BI-Based Automatic Optimizer: BigQuery’s intelligent optimizer automatically analyzes query patterns and applies optimizations without manual intervention:
- Query Plan Optimization: Automatically selects optimal execution plans based on data statistics and query patterns
- Adaptive Query Execution: Dynamically adjusts query execution strategies based on runtime conditions
- Cost-Based Optimization: Considers both performance and cost factors when optimizing queries
- Statistics-Driven Decisions: Uses table and column statistics to make intelligent optimization choices
- History-Based Optimization: BigQuery learns from historical query patterns to improve future query performance:
- Query Pattern Recognition: Identifies frequently used query patterns and optimizes execution paths
- Resource Allocation: Optimizes resource allocation based on historical workload patterns
- Predictive Caching: Proactively caches results based on predicted query patterns
- Workload-Aware Optimization: Adapts optimization strategies based on workload characteristics
- BI Engine Integration for Dashboard Performance: Use BI Engine to accelerate dashboard and visualization performance through in-memory caching:
- Sub-second Query Response: Achieve sub-second response times for dashboard queries
- Automatic Data Acceleration: Automatically identifies and accelerates frequently accessed data
- Visualization Optimization: Optimizes queries specifically for business intelligence tools
- Memory-Based Caching: Uses high-speed memory to cache frequently accessed data
7. Machine Learning Integration with BigQuery ML
BigQuery ML enables organizations to build, train, and deploy machine learning models directly within the data warehouse environment.
BigQuery ML Model Development
Model Types and Use Cases:
- Linear Regression: Predict continuous values (sales forecasting, price prediction)
- Classification: Categorize data (customer segmentation, churn prediction)
- Clustering: Group similar data points (market segmentation, anomaly detection)
- Time Series Forecasting: Predict future values based on historical patterns
- Deep Neural Networks: Complex pattern recognition and prediction tasks
8. Scalability and Performance Tuning
Ensuring scalability and optimal performance is critical for a BigQuery DW that can grow with organizational needs.
- Optimize Slot Allocation:
- Slot Reservations vs. Pay-as-you-go: Use BigQuery Reservations to allocate compute resources efficiently for predictable workloads, while using on-demand pricing for ad hoc analysis and variable workloads
- Workload Management: Implement workload management strategies to balance resource allocation across different types of analytical workloads
- Performance Monitoring: Monitor slot utilization and query performance to optimize resource allocation
- Leverage Federated Queries:
- BigLake Integration: Use BigLake and external tables for querying across storage solutions like Cloud Storage and Cloud SQL, enabling a unified analytics platform
- Multi-cloud Strategy: Implement multi-cloud data integration strategies for comprehensive analytics
- Real-time Integration: Develop real-time data integration pipelines for time-sensitive analytics
- Use Multi-Region Deployments:
- Global Accessibility: Store data in multi-regions for global accessibility and reduced latency
- Disaster Recovery: Implement disaster recovery strategies with multi-region data replication
- Compliance: Ensure multi-region deployments meet data sovereignty and compliance requirements
Our Work – Case Study
- Data Warehousing Solution for Automotive Client: A major Indian automotive conglomerate was looking to build a scalable data solution that integrates data from diverse sources like SAP, Oracle/SQL, and APIs to support real-time analytics and business reporting. We enabled advanced data analytics with BigQuery on Google Cloud, empowering their business users with secure, real-time access to insights for enterprise-wide, data-driven decision-making. Key components included BigQuery for fast query processing, Dataflow and Composer for aggregation and orchestration, and Cloud Run and Cloud Storage for API data and backups. By following BigQuery data warehouse best practices, we ensured a secure, high-performance analytics platform with optimal cost-efficiency and scalability.
- BigQuery Optimization To Improve Cost & Scalability For A Leading Automotive Manufacturing Company: A leading Indian automotive and tractor manufacturing company addressed high infrastructure costs and limited scalability in their analytics platform used by farm operators. The client faced high infrastructure expenses due to frequent read/write operations and VM-based deployments. The client needed a cost-effective, scalable solution to handle heavy read/write operations from real-time tractor data. Niveus implemented a cloud-native architecture using Google Cloud services like BigQuery, Dataflow, Cloud Run, and Bigtable, along with a customized optimization algorithm and Carto API integration. This enabled real-time data ingestion, efficient processing, and dynamic scaling. As a result, the client achieved a 90% reduction in data processing costs, improved performance, and streamlined infrastructure management transforming their analytics system into a high-performing, scalable, and cost-efficient platform.
- Redefining Data Strategy: Optimized Analytics with BigQuery: India’s largest car-sharing marketplace wanted to modernize their data infrastructure, as the client faced performance slowdowns, high data volume challenges, and difficulty in tracing issues across AWS Redshift and Athena. To enhance analytics efficiency and governance, Niveus executed a seamless migration to Google BigQuery, transferring 2.3 TB of historical data, over 5,000 tables, and 27 pipeline jobs. By consolidating all workloads into a unified, cloud-native platform, the solution enabled a single source of truth, faster performance, and simplified data access and processing driving greater operational efficiency and analytical accuracy across the organization.
- Improving Data Insights with Query Optimization on BigQuery: A fast-growing social e-commerce platform needed to optimize their BigQuery environment to reduce operational costs and improve data performance following a Redshift migration. Niveus translated and manually optimized queries using BigQuery Views and created a reporting dataset that integrated seamlessly with Redash, Superset, and Tableau. This optimization delivered a 99% improvement in query response time, reduced maintenance complexity, and significantly enhanced the customer experience. The solution empowered the client to make faster, data-driven decisions while strengthening brand trust and operational efficiency.
Conclusion
Designing an efficient data warehouse in BigQuery requires careful consideration of schema design, data ingestion, query optimization, cost control, security, and scalability. The practices outlined in this guide provide a comprehensive framework for building robust, performant, and cost-effective BigQuery data warehouse solutions.
Incorporating these BigQuery data warehouse best practices into your work with BigQuery will help manage costs while also enhancing the performance, security, and scalability of your data analytics projects.In fact, organizations that follow cloud-native data warehousing best practices have reported up to a 40% improvement in query performance and a 30–50% reduction in total cost of ownership, according to industry benchmarks and surveys. Regular monitoring, continuous optimization, and staying current with BigQuery’s evolving capabilities will ensure your data warehouse continues to meet organizational needs as they grow and change.
Data warehouse design is an iterative process. Start with core best practices, monitor performance and costs, and continuously refine your approach based on usage patterns and business requirements. The flexibility and power of BigQuery, combined with these comprehensive best practices, will enable you to build a data warehouse that serves as a strategic asset for your organization’s analytics and decision-making capabilities. A recent industry report found that enterprises leveraging cloud platforms for data analytics saw a 26% increase in data-driven decision-making speed, highlighting the transformative impact of efficient warehouse design.









