


Data being one of the key drivers of innovation and growth these days, has placed greater emphasis on data-related solutions such as batch processing. Businesses are generating data by the terabytes and processing these in batches would be productive and less time-consuming. Building a robust data pipeline for supporting a batch processing system is quickly becoming a point of focus for businesses across industries. Here we will look at the basics of batch processing architecture and how you can get started with it.
Boost your business’s productivity with batch processing implementations by Niveus
What exactly is batch processing?
Batch processing is where you take a set of information or data and process it all, at the same time. It can be used to do all sorts of different things like moving files from point A to point B to running reports and analytics.
While it can be used for a variety of applications, most businesses use it to handle large projects, such as monthly tax filings, payroll processing, or annual reports. The process of batch processing is not new as it has been used in businesses for many years. Its architecture has gone through many changes over the years, but the current architecture is well established.
Building a batch processing system requires deep knowledge in regards to the various tools that are out there, and using the right ones for your business. The architecture varies in complexity and number of architectural layers, depending on a particular business task.
With Niveus, businesses can streamline the development activities that involve batch processing, so that the overall efficiency and turnaround time of the development activity can be improved from data ingestion, aggregation, storage, processing, visualization and analytics.
Standard Batch Processing on Google Cloud
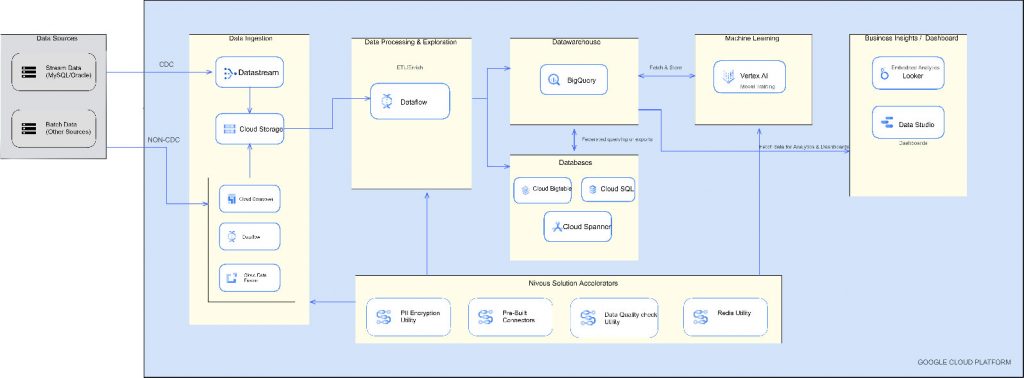
Niveus batch processing architecture components
At Niveus, the batch processing solution involves the following tools:
- Google Cloud Platform as the Cloud Service Platform
- Google Cloud Datastream for Change Data Capture (CDC)
- Google Cloud composer as the orchestration tool
- Apache Beam with Java, with Dataflow as the pipeline builder and runner respectively
- Google Cloud Function for event based triggers
- BigQuery as the Data warehouse tool
- Google Cloud Storage as the Storage Layer
- Memorystore for any In-memory state and lookups
- Looker as the Business intelligence / Reporting tool
Here’s how we build a GCP-enabled batch processing system from source to target –
Data ingestion: Leverage Datastream, which provides near-real-time access to changed data from a variety of on-premises and cloud-based data sources to create access to organizational data. Datastream currently supports streaming from Oracle and MySQL databases, by which Change Data Capture (CDC) can be achieved seamlessly with minimal latency. The cloud storage can be used for buffering data. In order to achieve CDC for data sources, where datastream connectivity is not supported yet, use Google Cloud Dataflow, and (or) composer with the help of an audit log table.
Transformation (Extract Transform Load): Google Cloud Dataflow enables fast, simplified and scalable data pipeline development with lower data latency. As described above, the cloud function can be used to trigger dataflow whenever a new file is placed in the storage. It is built on Google Cloud Dataflow with Apache beam to transform the ingested data. The transformation phase can serve a variety of purposes, such as making changes to the data format to add or remove a field, applying an index to the data, so it has better characteristics for serving jobs that consume the data or handling Personally Identifiable Information (PII) or sensitive data using encryption. The transformation layer prepares your data for further analysis or serving.
Warehouse: BigQuery – serverless, highly scalable, and cost-effective multi-cloud data warehouse designed for business agility, which enables analysis of petabytes of data using ANSI SQL at blazing-fast speeds, with zero operational overhead (pay-as-you-use model with cost, mostly determined by the amount of data queried). BigQuery features such as BigQuery ML, increase development speed by eliminating the need to move data. Moreover, BigQuery ML democratizes machine learning by letting SQL practitioners build models using existing SQL tools and skills.
Business Intelligence/Reporting: Reporting would ideally be done with Looker – business intelligence software and big data analytics platform that helps you explore, analyze and share real-time business analytics easily. It supports multiple data sources and deployment methods, providing more options without compromising on transparency, security, or privacy.
Data solution accelerators: Solution accelerators are ready-to-use data frameworks that help you develop data products faster.
Importance of Niveus’ solution accelerators
Solution accelerators (in-house data frameworks) fit into the larger data development life cycle which would accelerate the time-to-production. Here’s why solution accelerators are important –
- Faster development activity: Niveus’ in-house data solution frameworks would help you jump-start the development activity that would help in saving hours of development activity enabling you to go from ideation to Proof of Concept (PoC).
- Reduces development risks: Custom software development comes with a high level of risk as it requires building every feature from scratch. This is time-consuming and costly, and with no guarantee of the required outcome. Our in-house data accelerators help in building trusted components, which ensures reliability, scalability and responsiveness of applications.
- Address common business problems: Solution accelerators help in addressing common challenges, such as encrypting PII data, providing a secure interface to interact with other systems such as redis or authenticating users securely. these challenges efficiently.
Data security strategy
At Niveus, we take into consideration the different facets of data security while building a batch processing system including application security, network security, data security, monitoring and logging access and control. Google Cloud BI Platform (Looker), the Looker data is encrypted in transit and at rest using AES (Advanced Encryption Standard) Authentication.
Looker supports two-factor authentication and integrates with LDAP and industry standard single sign-on. It provides a single point of access for your data. Administrators can set a granular level of permission in accessing the data which provide three levels of data governance strategy: model, group and user. When the data is in motion, Looker communicates over industry-standard encryption and secure connections.
Advantages of batch processing :
Efficiency – Batch processing is an efficient way for businesses to handle multiple jobs, as it allows them to process jobs while computing or other resources that are readily available. This type of processing can be run at specified times, which gives businesses the ability to prioritize time-sensitive jobs. Additionally, batch processing can be run offline to reduce stress on processors.
Simplicity – It is a less complex system and requires less maintenance when compared to stream processing as it doesn’t require special hardware or system support for inputting data.
Improved data quality – It is a great way to automate most or all components of a processing job. This method minimizes user interaction and errors. As a result, precision and accuracy are improved to produce a higher degree of data quality.
Faster business intelligence – It speeds up big data processing time and delivers output quicker for business intelligence tools, so that companies can take action in a timely manner.
Processing data the right way plays a major role in leveraging the vast amounts of data churned by a business. If you want to learn more about Niveus Batch Processing system.









